API文档
本页自动汇总 sindre 库主要模块的全部 API,支持自动文档与交互查询。
LMDB模块API
Base
公共工具类
Reader
Bases: Base
用于读取包含张量(numpy.ndarray)数据集的对象。
这些张量是通过使用MessagePack从Lightning Memory-Mapped Database (LMDB)中读取的。
支持功能: - 读取使用新键管理系统存储的数据 - 兼容旧版本数据库格式 - 支持多进程读取 - 支持任意类型元数据读取 - 支持读取已删除的样本
Note
with Reader(dirpath='dataset.lmdb') as reader: # 基本读取操作 sample = reader[5] # 读取第5个样本 sample = reader.get_sample(5) # 读取第5个样本 samples = reader.get_samples([1,3,5]) # 读取多个样本
# 获取信息
mapping = reader.get_mapping() # 获取键映射关系
data_keys = reader.get_data_keys(0) # 获取数据键名
meta_keys = reader.get_meta_keys() # 获取元数据键名
# 特殊功能
deleted_sample = reader.get_delete_sample(10) # 读取已删除的样本
meta_value = reader.get_meta('key') # 读取元数据
__init__(dirpath, multiprocessing=False)
初始化
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
dirpath
|
包含LMDB的目录路径。 |
必需 | |
multiprocessing
|
是否开启多进程读取。 |
必需 |
get_data_keys(i)
返回第i个样本在data_db中的所有键的列表
Args:
i: 索引,默认检查第一个样本
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
list |
list
|
数据键名列表 |
get_data_size(i)
计算LMDB中单个样本的存储大小(MB) :param i: 索引 :return: 存储大小(MB)
get_data_specification(i)
返回第i个样本的所有数据对象的规范。
规范包括形状和数据类型。这假设每个数据对象都是numpy.ndarray。
Args:
i: 索引
Returns:
dict: 数据规范字典
get_data_value(i, key)
返回第i个样本对应于输入键的值。
该值从data_db中检索。
因为每个样本都存储在一个msgpack中,所以在返回值之前,我们需要先读取整个msgpack。
Args:
i: 索引
key: 该索引的键(支持多层路径,如"mesh.v")
Returns:
对应的值
Raises:
KeyError: 键不存在或路径无效时抛出
get_delete_sample(physical_key)
读取已删除的样本数据(通过物理键)
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
physical_key
|
int
|
物理键值 |
必需 |
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
dict |
dict
|
已删除的样本数据 |
引发:
| 类型 | 描述 |
|---|---|
ValueError
|
如果物理键不存在或未被标记为删除 |
get_dict_keys(nested_dict, parent_key='', sep='.')
提取嵌套字典中所有层级键,用分隔符连接后返回列表
:param nested_dict: 输入的嵌套字典 :param parent_key: 父级键(递归时使用,外部调用无需传参) :param sep: 键的分隔符,默认 "." :return: 扁平键列表(如 ['mesh.v', 'mesh.f'])
get_mapping(phy2log=True)
获取逻辑索引与物理键的映射关系
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
phy2log
|
bool
|
True=物理键到逻辑索引的映射关系,False=逻辑索引到物理键的映射关系 |
True
|
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
dict |
映射关系 {物理键: 逻辑索引} or {逻辑索引: 物理键} |
get_meta(key)
从元数据库读取任意类型的数据
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
key
|
键名 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
|
存储的数据,如果不存在则返回None |
get_meta_keys()
返回:
| 类型 | 描述 |
|---|---|
set
|
获取元数据库所有键 |
get_sample(i)
从data_db返回第i个样本(逻辑索引)
Args:
i: 逻辑索引
Returns:
dict: 样本数据字典
Raises:
IndexError: 如果索引超出范围
get_samples(keys)
list所有连续样本 Args: keys: 需要返回的索引对应的数据
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
list |
list
|
所有样本组成的列表 |
引发:
| 类型 | 描述 |
|---|---|
IndexError
|
如果索引范围超出边界 |
ReaderList
组合多个LMDB数据库进行统一读取的类,提供序列协议的接口
该类用于将多个LMDB数据库合并为一个逻辑数据集,支持通过索引访问和获取长度。 内部维护数据库索引映射表和真实索引映射表,实现跨数据库的透明访问。
属性:
| 名称 | 类型 | 描述 |
|---|---|---|
db_list |
List[Reader]
|
存储打开的LMDB数据库实例列表 |
db_mapping |
List[int]
|
索引到数据库索引的映射表,每个元素表示对应索引数据所在的数据库下标 |
real_idx_mapping |
List[int]
|
索引到数据库内真实索引的映射表,每个元素表示数据在对应数据库中的原始索引 |
__del__()
析构函数,自动调用close方法释放资源
注意:不保证析构函数会被及时调用,建议显式调用close()
__getitem__(idx)
通过索引获取数据条目
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
idx
|
int
|
数据条目在组合数据集中的逻辑索引 |
必需 |
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
object |
对应位置的数据条目,具体类型取决于LMDB存储的数据格式 |
引发:
| 类型 | 描述 |
|---|---|
IndexError
|
当索引超出组合数据集范围时抛出 |
__init__(db_path_list, multiprocessing=True)
初始化组合数据库读取器
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
db_path_list
|
List[str]
|
LMDB数据库文件路径列表,按顺序加载每个数据库 |
必需 |
__len__()
获取组合数据集的总条目数
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
int |
int
|
所有LMDB数据库的条目数之和 |
close()
关闭所有打开的LMDB数据库连接
该方法应在使用完毕后显式调用,确保资源正确释放
ReaderSSD
针对SSD优化的LMDB数据库读取器,支持高效随机访问
该类针对SSD存储特性优化,每次读取时动态打开数据库连接, 适合需要高并发随机访问的场景,可充分利用SSD的IOPS性能。
属性:
| 名称 | 类型 | 描述 |
|---|---|---|
db_len |
int
|
数据库条目总数 |
db_path |
str
|
LMDB数据库文件路径 |
multiprocessing |
bool
|
是否启用多进程模式 |
__getitem__(idx)
通过索引获取单个数据条目
每次调用时动态打开数据库连接,读取完成后立即关闭。 适合随机访问模式,特别是在SSD存储上。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
idx
|
int
|
数据条目索引 |
必需 |
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
object |
object
|
索引对应的数据条目 |
引发:
| 类型 | 描述 |
|---|---|
IndexError
|
当索引超出有效范围时抛出 |
__init__(db_path, multiprocessing=False)
初始化SSD优化的LMDB读取器
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
db_path
|
str
|
LMDB数据库文件路径 |
必需 |
multiprocessing
|
bool
|
是否启用多进程支持。 启用后将允许在多个进程中同时打开数据库连接。默认为False。 |
False
|
__len__()
获取数据库的总条目数
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
int |
int
|
数据库中的条目总数 |
get_batch(indices)
批量获取多个数据条目
优化的批量读取接口,在一个数据库连接中读取多个条目, 减少频繁打开/关闭连接的开销。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
indices
|
list[int]
|
数据条目索引列表 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
|
list[object]: 索引对应的数据条目列表 |
引发:
| 类型 | 描述 |
|---|---|
IndexError
|
当任何索引超出有效范围时抛出 |
ReaderSSDList
组合多个SSD优化的LMDB数据库进行统一读取的类,提供序列协议的接口
该类用于将多个SSD优化的LMDB数据库合并为一个逻辑数据集,支持通过索引访问和获取长度。 内部维护数据库索引映射表和真实索引映射表,实现跨数据库的透明访问,同时保持SSD优化特性。
属性:
| 名称 | 类型 | 描述 |
|---|---|---|
db_path_list |
List[str]
|
LMDB数据库文件路径列表 |
db_mapping |
List[int]
|
索引到数据库索引的映射表,每个元素表示对应索引数据所在的数据库下标 |
real_idx_mapping |
List[int]
|
索引到数据库内真实索引的映射表,每个元素表示数据在对应数据库中的原始索引 |
multiprocessing |
bool
|
是否启用多进程模式 |
__getitem__(idx)
通过索引获取数据条目
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
idx
|
int
|
数据条目在组合数据集中的逻辑索引 |
必需 |
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
object |
对应位置的数据条目,具体类型取决于LMDB存储的数据格式 |
引发:
| 类型 | 描述 |
|---|---|
IndexError
|
当索引超出组合数据集范围时抛出 |
__init__(db_path_list, multiprocessing=False)
初始化组合SSD优化数据库读取器
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
db_path_list
|
List[str]
|
LMDB数据库文件路径列表,按顺序加载每个数据库 |
必需 |
multiprocessing
|
bool
|
是否启用多进程支持。默认为False。 |
False
|
__len__()
获取组合数据集的总条目数
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
int |
int
|
所有LMDB数据库的条目数之和 |
get_batch(indices)
批量获取多个数据条目
对同一数据库中的索引进行分组,然后使用对应数据库的get_batch方法批量读取, 减少频繁打开/关闭连接的开销。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
indices
|
list[int]
|
数据条目索引列表 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
|
list[object]: 索引对应的数据条目列表 |
引发:
| 类型 | 描述 |
|---|---|
IndexError
|
当任何索引超出有效范围时抛出 |
Writer
Bases: Base
用于将数据集的对象 ('numpy.ndarray') 写入闪电内存映射数据库 (LMDB),并带有MessagePack压缩。
功能特点: - 支持数据的保存、修改、删除、插入操作 - 使用双键管理系统:物理键和逻辑键分离 - 标记删除而非物理删除,支持数据恢复 - 兼容旧版本数据库格式 - 支持多进程模式
Note
db = Writer(dirpath=r'datasets/lmdb.db', map_size_limit=1024*100)
元数据操作
db.put_meta_("描述信息", "xxxx") db.put_meta_("元信息",{"version”:"1.0.0","list":[1,2]}) db.put_meta_("列表",[1,2,3])
基本操作
data = {xx:np.array(xxx)} db.put_sample(data) # 在末尾添加样本 db.insert_sample(5, data) # 在指定位置插入样本 db.change_sample(3, data) # 修改指定位置的样本 db.delete_sample(2) # 标记删除指定位置的样本 db.restore_sample(10) # 恢复已删除的样本 db.close()
physical_size
property
物理存储大小
size
property
数据库大小(有效样本数)- 与 nb_samples 保持一致
__init__(dirpath, map_size_limit, multiprocessing=False)
初始化
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
dirpath
|
str
|
应该写入LMDB的目录的路径。 |
必需 |
map_size_limit
|
int
|
LMDB的map大小,单位为MB。必须足够大以捕获打算存储在LMDB中所有数据。 |
必需 |
change_sample(key, sample, safe_model=True)
修改键值
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
key
|
int
|
键 |
必需 |
sample
|
dict
|
字典类型数据 |
必需 |
safe_model
|
bool
|
安全模式,如果开启,则修改会提示; |
True
|
close()
关闭环境。
在关闭之前,将样本数写入meta_db,使所有打开的迭代器、游标和事务无效。
delete_sample(key)
删除指定逻辑索引位置的样本(标记删除)
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
key
|
int
|
要删除的逻辑索引位置 |
必需 |
get_mapping(phy2log=True)
获取逻辑索引与物理键的映射关系 Args: phy2log:True=物理键到逻辑索引的映射关系,False=逻辑索引到物理键的映射关系
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
dict |
映射关系{物理键: 逻辑索引} or {逻辑索引: 物理键} |
insert_sample(key, sample, safe_model=True)
在指定逻辑索引位置插入样本
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
key
|
int
|
要插入的逻辑索引位置 |
必需 |
sample
|
dict
|
要插入的样本数据 |
必需 |
safe_model
|
bool
|
安全模式,如果开启则会提示确认 |
True
|
put_meta(key, value)
将任意类型的数据写入元数据库
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
key
|
str
|
键名 |
必需 |
value
|
任意可序列化的数据(支持str、list、dict等) |
必需 |
put_sample(sample)
将传入内容的键和值放入data_db LMDB中。
Notes
put_samples({'key1': value1, 'key2': value2, ...})
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
sample
|
dict
|
由str为键,numpy类型为值组成 |
必需 |
restore_sample(physical_key)
恢复标记删除的样本
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
physical_key
|
int
|
要恢复的物理键 |
必需 |
fix_lmdb_windows_size(dirpath)
修复lmdb在windows系统上创建大小异常问题(windows上lmdb没法实时变化大小);
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
dirpath
|
str
|
lmdb目录路径 |
必需 |
Returns:
get_data_size(samples)
检测sample字典的大小
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
samples
|
_type_
|
字典类型数据 |
必需 |
Return
gb_required : 字典大小(GB)
get_data_value(current, key)
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
key
|
该索引的键(支持多层路径,如"mesh.v") |
必需 |
Returns: 对应的值 Raises: KeyError: 键不存在或路径无效时抛出
merge_lmdb(target_dir, source_dirs, map_size_limit, multiprocessing=False)
将多个源LMDB数据库合并到目标数据库
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
target_dir
|
str
|
目标LMDB路径 |
必需 |
source_dirs
|
list
|
源LMDB路径列表 |
必需 |
map_size_limit
|
int
|
目标LMDB的map大小限制(MB) |
必需 |
multiprocessing
|
bool
|
是否启用多进程模式 |
False
|
Example
# 合并示例
MergeLmdb(
target_dir="merged.db",
source_dirs=["db1", "db2"],
map_size_limit=1024 # 1GB
)
parallel_write(output_dir, file_list, process, map_size_limit, num_processes, multiprocessing=False, temp_root='./tmp', cleanup_temp=True)
多进程处理JSON文件并写入LMDB
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
output_dir
|
str
|
最终输出LMDB路径 |
必需 |
file_list
|
list
|
文件路径列表 |
必需 |
process
|
callable
|
数据处理函数 |
必需 |
map_size_limit
|
int
|
总LMDB的map大小限制(MB) |
必需 |
num_processes
|
int
|
进程数量 |
必需 |
multiprocessing
|
bool
|
是否启用多进程模式 |
False
|
temp_root
|
str
|
临时目录根路径(默认./tmp,尽量写在SSD,方便快速转换 |
'./tmp'
|
cleanup_temp
|
bool
|
是否清理临时目录(默认True) |
True
|
Example
def process(json_file):
with open(json_file,"r") as f:
data = json.loads(f.read())
id=data["id_patient"]
jaw = data["jaw"]
labels = data["labels"]
mesh = vedo.load( json_file.replace(".json",".obj"))
vertices = mesh.vertices
faces = mesh.cells
out = {
'mesh_faces':faces,
'mesh_vertices':vertices,
'vertex_labels':labels,
"jaw":jaw,
}
return out
if __name__ == '__main__':
json_file_list = glob.glob("./*/*/*.json")
print(len(json_file_list))
sindre.lmdb.parallel_write(
output_dir=dirpath,
file_list=json_file_list[:16],
process=process,
map_size_limit=map_size_limit,
num_processes=8,
temp_root="./processing_temp",
cleanup_temp=False
)
split_lmdb(source_dir, target_dirs, map_size_limit, multiprocessing=False)
将源LMDB数据库均匀拆分到多个目标数据库
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
source_dir
|
str
|
源LMDB路径 |
必需 |
target_dirs
|
list
|
目标LMDB路径列表 |
必需 |
map_size_limit
|
int
|
每个目标LMDB的map大小限制(MB) |
必需 |
multiprocessing
|
bool
|
是否启用多进程模式 |
False
|
Example
SplitLmdb(
source_dir="large.db",
target_dirs=[f"split_{i}.db" for i in range(4)],
map_size_limit=256
)
check_filesystem_is_ext4(current_path)
检测硬盘是否为ext4
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
current_path
|
str
|
需要检测的磁盘路径 |
必需 |
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
True |
bool
|
当前为ext4磁盘,支持自适应容量分配 |
False |
bool
|
当前不是ext4磁盘,不支持自适应容量分配 |
decode_data(obj)
解码一个序列化的数据对象。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
obj
|
Python 字典 一个描述序列化数据对象的字典。 |
必需 |
decode_str(obj, encoding='utf-8', errors='strict')
将输入字节对象解码为字符串。
Parameters
obj : byte object
encoding : string
Default is utf-8.
errors : string
指定应如何处理编码错误。默认为 strict.
encode_data(obj)
返回一个字典,该字典包含对输入数据对象进行编码后的信息。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
obj
|
数据对象 如果传入的数据对象既不是字符串也不是普通的 NumPy 数组, 则该对象将按原样返回。 |
必需 |
encode_str(string, encoding='utf-8', errors='strict')
返回输入字符串的编码字节对象。
Parameters
string : string
encoding : string
Default is utf-8.
errors : string
指定应如何处理编码错误。默认为 strict.
三维算法API
@path :sindre_package -> tools.py
@IDE :PyCharm
@Author :sindre
@Email :yx@mviai.com
@Date :2024/6/17 15:38
@Version: V0.1
@License: (C)Copyright 2021-2023 , UP3D
@Reference:
@History:
- 2024/6/17 :
(一)本代码的质量保证期(简称“质保期”)为上线内 1个月,质保期内乙方对所代码实行包修改服务。
(二)本代码提供三包服务(包阅读、包编译、包运行)不包熟
(三)本代码所有解释权归权归神兽所有,禁止未开光盲目上线
(四)请严格按照保养手册对代码进行保养,本代码特点:
i. 运行在风电、水电的机器上
ii. 机器机头朝东,比较喜欢太阳的照射
iii. 集成此代码的人员,应拒绝黄赌毒,容易诱发本代码性能越来越弱
声明:未履行将视为自主放弃质保期,本人不承担对此产生的一切法律后果
如有问题,热线: 114
A_Star
__init__(vertices, faces)
使用A*算法在三维三角网格中寻找最短路径
参数: vertices: numpy数组,形状为(N,3),表示顶点坐标 faces: numpy数组,形状为(M,3),表示三角形面的顶点索引
build_adjacency(faces)
构建顶点的邻接表
run(start_idx, end_idx, vertex_weights=None)
使用A*算法在三维三角网格中寻找最短路径
参数: start_idx: 起始顶点的索引 end_idx: 目标顶点的索引 vertex_weights: 可选,形状为(N,),顶点权重数组,默认为None
返回: path: 列表,表示从起点到终点的顶点索引路径,若不可达返回None
BestKFinder
__init__(points, labels)
初始化类,接收点云网格数据和对应的标签
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
points
|
ndarray
|
点云数据,形状为 (N, 3) |
必需 |
labels
|
ndarray
|
点云标签,形状为 (N,) |
必需 |
calculate_boundary_points(k)
计算边界点 :param k: 最近邻点的数量 :return: 边界点的标签数组
evaluate_boundary_points(bd_labels)
评估边界点的分布合理性 这里简单使用边界点的数量占比作为评估指标 :param bd_labels: 边界点的标签数组 :return: 评估得分
find_best_k(k_values)
找出最佳的最近邻点大小
:param k_values: 待测试的最近邻点大小列表 :return: 最佳的最近邻点大小
GraphCutWithMesh
__init__(tri_mesh, softmax_labels, smooth_factor=None, keep_label=True)
基于图切优化器,支持顶点/面片级别优化
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
tri_mesh
|
Trimesh
|
trimesh.Trimesh格式的mesh |
必需 |
softmax_labels
|
ndarray
|
softmax后的概率矩阵,形状为: - 顶点模式:(Nv, class_num) - 面片模式:(Nf, class_num) |
必需 |
smooth_factor
|
float
|
平滑强度系数,越大边界越平滑。默认值为 None,此时会自动计算。 |
None
|
keep_label
|
bool
|
是否保持优化前后标签类别一致性,默认值为 True。 |
True
|
get_weights()
计算顶点间边权
refine()
执行优化并返回优化后的标签索引
LabelUpsampler
__init__(classifier_type='gbdt', knn_params={'n_neighbors': 3}, gbdt_params={'n_estimators': 100, 'max_depth': 5})
标签上采样,用于将简化后的标签映射回原始网格/点云
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
classifier_type
|
str, optional (default='gbdt') 分类器类型,支持 'knn', 'gbdt', 'hgbdt', 'rfc' |
必需 | |
knn_params
|
dict, optional KNN分类器参数,默认 {'n_neighbors': 3} |
必需 | |
gbdt_params
|
dict, optional GBDT/HGBDT/RFC分类器参数,默认 {'n_estimators': 100, 'max_depth': 5} |
必需 |
fit(train_features, train_labels)
训练模型: 建议: 点云: 按照[x,y,z,nx,ny,nz,cv] # 顶点坐标+顶点法线+曲率+其他特征 网格: 按照[bx,by,bz,fnx,fny,fny] # 面片重心坐标+面片法线+其他特征
predict(query_features)
预测标签,输入特征应与训练特征一一对应;
MeshRandomWalks
__init__(vertices, faces, face_normals=None)
随机游走分割网格
参考:https://www.cnblogs.com/shushen/p/5144823.html
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
vertices
|
顶点坐标数组,形状为(N, 3) |
必需 | |
faces
|
面片索引数组,形状为(M, 3) |
必需 | |
face_normals
|
可选的面法线数组,形状为(M, 3) |
None
|
Note:
```python
# 加载并预处理网格
mesh = vedo.load(r"upper_jaws.ply")
mesh.compute_normals()
# 创建分割器实例
segmenter = MeshRandomWalks(
vertices=mesh.points,
faces=mesh.faces(),
face_normals=mesh.celldata["Normals"]
)
head = [1063,3571,1501,8143]
tail = [7293,3940,8021]
# 执行分割
labels, unmarked = segmenter.segment(
foreground_seeds=head,
background_seeds=tail
)
p1 = vedo.Points(mesh.points[head],r=20,c="red")
p2 = vedo.Points(mesh.points[tail],r=20,c="blue")
# 可视化结果
mesh.pointdata["labels"] = labels
mesh.cmap("jet", "labels")
vedo.show([mesh,p1,p2], axes=1, viewup='z').close()
```
segment(foreground_seeds, background_seeds, vertex_weights=None)
执行网格分割
参数
foreground_seeds: 前景种子点索引列表 background_seeds: 背景种子点索引列表 vertex_weights: 可选的顶点权重矩阵(稀疏矩阵)
返回
labels: 顶点标签数组 (0: 背景,1: 前景) unmarked: 未标记顶点的布尔掩码
NpEncoder
Bases: JSONEncoder
Notes
将numpy类型编码成json格式
UnifiedLabelRefiner
__init__(vertices, faces, labels, class_num, smooth_factor=None, temperature=None)
统一多标签优化器,支持顶点/面片概率输入
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
vertices
|
ndarray
|
顶点坐标数组,形状 (Nv, 3) |
必需 |
faces
|
ndarray
|
面片索引数组,形状 (Nf, 3) |
必需 |
labels
|
ndarray
|
初始标签,可以是类别索引(一维)(n,) 或概率矩阵,形状为: - 顶点模式:(Nv, class_num) - 面片模式:(Nf, class_num) |
必需 |
class_num
|
int
|
总类别数量(必须等于labels.shape[1]) |
必需 |
smooth_factor
|
float
|
边权缩放因子,默认自动计算 |
None
|
temperature
|
float
|
标签软化温度(None表示不软化) |
None
|
refine()
执行优化并返回优化后的标签索引
add_base(vd_mesh, value_z=-20, close_base=True, return_strips=False)
给网格边界z方向添加底座
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
vd_mesh
|
_type_
|
vedo.mesh |
必需 |
value_z
|
int
|
底座长度. Defaults to -20. |
-20
|
close_base
|
bool
|
底座是否闭合. Defaults to True. |
True
|
return_strips
|
bool
|
是否返回添加的网格. Defaults to False. |
False
|
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
_type_ |
添加底座的网格 |
angle_axis_np(angle, axis)
计算绕给定轴旋转指定角度的旋转矩阵。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
angle
|
float
|
旋转角度(弧度)。 |
必需 |
axis
|
ndarray
|
旋转轴,形状为 (3,) 的 numpy 数组。 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
|
np.array: 3x3 的旋转矩阵,数据类型为 np.float32。 |
apply_transform(vertices, transform)
对4*4矩阵进行应用
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
vertices
|
array
|
顶点 |
必需 |
transform
|
array
|
4*4 矩阵 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
array
|
变换后的顶点 |
array2voxel(voxel_array)
将固定大小的三维数组转换为 voxel_grid_index 数组。
该函数接收一个形状为 (voxel_size, voxel_size, voxel_size) 的三维数组,
找出其中值为 1 的元素的索引,将这些索引组合成一个形状为 (N, 3) 的数组,
类似于从 open3d 的 o3d.voxel_grid.get_voxels () 方法获取的结果。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
voxel_array
|
ndarray
|
形状为 (voxel_size, voxel_size, voxel_size) 的三维数组,数组中值为 1 的位置代表对应的体素网格索引。 |
必需 |
Returns:
numpy.ndarray: 形状为 (N, 3) 的数组,表示三维空间中每个体素的网格索引,类似于从 o3d.voxel_grid.get_voxels () 方法获取的结果。
Example:
```python
# 获取 grid_index_array
voxel_list = voxel_grid.get_voxels()
grid_index_array = list(map(lambda x: x.grid_index, voxel_list))
grid_index_array = np.array(grid_index_array)
voxel_grid_array = voxel2array(grid_index_array, voxel_size=32)
grid_index_array = array2voxel(voxel_grid_array)
pointcloud_array = grid_index_array # 0.03125 是体素大小
pc = o3d.geometry.PointCloud()
pc.points = o3d.utility.Vector3dVector(pointcloud_array)
o3d_voxel = o3d.geometry.VoxelGrid.create_from_point_cloud(pc, voxel_size=0.05)
o3d.visualization.draw_geometries([pcd, cc, o3d_voxel])
```
collision_depth(mesh1, mesh2)
计算两个网格间的碰撞深度或最小间隔距离。
使用VTK的带符号距离算法检测碰撞状态: - 正值:两网格分离,返回值为最近距离 - 零值:表面恰好接触 - 负值:发生穿透,返回值为最大穿透深度(绝对值)
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
mesh1
|
Mesh
|
第一个网格对象,需包含顶点数据 |
必需 |
mesh2
|
Mesh
|
第二个网格对象,需包含顶点数据 |
必需 |
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
float |
float
|
带符号的距离值,符号表示碰撞状态,绝对值表示距离量级 |
引发:
| 类型 | 描述 |
|---|---|
RuntimeError
|
当VTK计算管道出现错误时抛出 |
Notes
- 当输入网格顶点数>1000时会产生性能警告
- 返回float('inf')表示计算异常或无限远距离
color_mapping(value, vmin=-1, vmax=1)
将向量映射为颜色,遵从vcg映射标准
compute_curvature_by_igl(v, f, method='Mean')
用igl计算平均曲率并归一化
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
v
|
顶点; |
必需 | |
f
|
面片: |
必需 | |
method
|
返回曲率类型 |
'Mean'
|
返回:
| 类型 | 描述 |
|---|---|
|
Notes:
输出: PD1 (主方向1), PD2 (主方向2), PV1 (主曲率1), PV2 (主曲率2)
pd1 : #v by 3 maximal curvature direction for each vertex
pd2 : #v by 3 minimal curvature direction for each vertex
pv1 : #v by 1 maximal curvature value for each vertex
pv2 : #v by 1 minimal curvature value for each vertex
compute_curvature_by_meshlab(ms)
使用 MeshLab 计算网格的曲率和顶点颜色。
该函数接收一个顶点矩阵和一个面矩阵作为输入,创建一个 MeshLab 的 MeshSet 对象, 并将输入的顶点和面添加到 MeshSet 中。然后,计算每个顶点的主曲率方向, 最后获取顶点颜色矩阵和顶点曲率数组。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
ms
|
pymeshlab格式mesh; |
必需 |
返回:
| 类型 | 描述 |
|---|---|
|
|
|
|
|
compute_face_normals(vertices, faces)
计算三角形网格中每个面的法线 Args: vertices: 顶点数组,形状为 (N, 3) faces: 面数组,形状为 (M, 3),每个面由三个顶点索引组成 Returns: 面法线数组,形状为 (M, 3)
compute_vertex_normals(vertices, faces)
计算三角形网格中每个顶点的法线 Args: vertices: 顶点数组,形状为 (N, 3) faces: 面数组,形状为 (M, 3),每个面由三个顶点索引组成 Returns: 顶点法线数组,形状为 (N, 3)
create_voxels(vertices, resolution=256)
通过顶点创建阵列方格体素
Args: vertices: 顶点 resolution: 分辨率
返回:
| 类型 | 描述 |
|---|---|
|
返回 res**3 的顶点 , mc重建需要的缩放及位移 |
Notes
v, f = mcubes.marching_cubes(data.reshape(256, 256, 256), 0)
m=vedo.Mesh([v*scale+translation, f])
cut_mesh_point_loop(mesh, pts, invert=False)
基于vtk+dijkstra实现的基于线的分割;
线支持在网格上或者网格外;
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
mesh
|
_type_
|
待切割网格 |
必需 |
pts
|
Points
|
切割线 |
必需 |
invert
|
bool
|
选择保留外部. Defaults to False. |
False
|
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
_type_ |
切割后的网格 |
cut_mesh_with_meshlib(v, f, loop_points, get_bigger_part=False, smooth_boundary=False)
沿指定的点环切割网格并返回选定的部分
给定的点环投影到网格表面,创建闭合轮廓,沿此轮廓切割网格, 并返回网格的较大或较小部分。可选择对切割边界进行平滑处理。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
v
|
ndarray
|
输入网格的顶点坐标,形状为 (N, 3) |
必需 |
f
|
ndarray
|
输入网格的面索引,形状为 (M, 3) |
必需 |
loop_points
|
定义切割环的3D点列表,每个点为 [x, y, z],,形状为 (B, 3) |
必需 | |
get_bigger_part
|
bool
|
如果为True,返回切割后较大的部分;否则返回较小的部分 |
False
|
smooth_boundary
|
bool
|
如果为True,对切割边界进行平滑处理 |
False
|
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
tuple |
tuple
|
包含: kept_mesh_v: 切割后网格的顶点坐标,形状为 (P, 3) kept_mesh_f: 切割后网格的面索引,形状为 (Q, 3) removed_mesh_v: 其他网格的顶点坐标,形状为 (P, 3) removed_mesh_f: 其他网格的面索引,形状为 (Q, 3) |
引发:
| 类型 | 描述 |
|---|---|
RuntimeError
|
如果切割操作失败或产生无效结果 |
Example
kept_mesh_v,kept_mesh_f,removed_mesh_v,removed_mesh_f = cut_mesh(vertices, faces, margin_points, get_bigger_part=True, smooth_boundary=True)
depth2color(depth, bg_color=None)
将深度值转换为彩色图像
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
depth
|
ndarray
|
深度值 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
ndarray
|
彩色深度图像,形状为(H, W, 3) |
detect_boundary_points(points, labels, config=None)
基于局部标签一致性的边界点检测函数
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
points
|
ndarray
|
点云坐标,形状为 (N, 3) |
必需 |
labels
|
ndarray
|
点云标签,形状为 (N,) |
必需 |
config
|
dict
|
配置参数,包含: - knn_k: KNN查询的邻居数(默认40) - bdl_ratio: 边界判定阈值(默认0.8) |
None
|
返回:
| 类型 | 描述 |
|---|---|
|
np.ndarray: 边界点掩码,形状为 (N,),边界点为True,非边界点为False |
equidistant_mesh(mesh, d=-0.01, merge=True)
此函数用于创建一个与输入网格等距的新网格,可选择将新网格与原网格合并。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
mesh
|
Mesh
|
输入的三维网格对象。 |
必需 |
d
|
(float, 可选)
|
顶点偏移的距离,默认为 -0.01。负值表示向内偏移,正值表示向外偏移。 |
-0.01
|
merge
|
(bool, 可选)
|
是否将原网格和偏移后的网格合并,默认为 True。 |
True
|
返回:
| 类型 | 描述 |
|---|---|
|
vedo.Mesh 或 vedo.Assembly: 如果 merge 为 True,则返回合并后的网格;否则返回偏移后的网格。 |
face_labels_to_vertex_labels(vertices, faces, face_labels)
将三角网格的面片标签转换成顶点标签
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
vertices
|
Union[array, list]
|
牙颌三角网格 |
必需 |
faces
|
Union[array, list]
|
面片标签 |
必需 |
face_labels
|
array
|
顶点标签 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
array
|
顶点属性 |
face_probs_to_vertex_probs(faces, face_probs, n_vertices)
将面片概率矩阵转换为顶点概率矩阵(使用max方法)
farthest_point_sampling(vertices, n_sample=2000, auto_seg=False, n_batches=10)
最远点采样,支持自动分批处理
根据参数配置,自动决定是否将输入点云分割为多个批次进行处理。当处理大规模数据时, 建议启用auto_seg以降低内存需求并利用并行加速。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
vertices
|
ndarray
|
输入点云坐标,形状为(N, 3)的浮点数组 |
必需 |
n_sample
|
int
|
总采样点数,当auto_seg=False时生效。默认2000 |
2000
|
auto_seg
|
bool
|
是否启用自动分批处理(提速,但会丢失全局距离信息)。默认False |
False
|
n_batches
|
int
|
自动分批时的批次数量。默认10 |
10
|
返回:
| 类型 | 描述 |
|---|---|
ndarray
|
np.ndarray: 采样点索引数组,形状为(n_sample,) |
引发:
| 类型 | 描述 |
|---|---|
ValueError
|
当输入数组维度不正确时抛出 |
Notes
典型场景: - 小规模数据(如5万点以下): auto_seg=False,单批次处理 - 大规模数据(如百万级点): auto_seg=True,分10批处理,每批采样2000点
示例:
vertices = np.random.rand(100000, 3).astype(np.float32)
自动分10批,每批采2000点
indices = farthest_point_sampling(vertices, auto_seg=True)
单批采5000点
indices = farthest_point_sampling(vertices, n_sample=5000)
farthest_point_sampling_by_open3d(vertices, n_sample=2000, device='CPU:0')
基于Open3D的最远点采样算法,返回采样点的索引数组
该函数利用Open3D库的高效实现,从输入的点云中按最远点策略采样指定数量的点, 并返回这些采样点在原始点云中的索引,便于后续还原采样前的点云数据。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
vertices
|
ndarray
|
输入点云数据,形状为[N, 3]的numpy数组,其中N为点的数量,3对应xyz坐标 |
必需 |
n_sample
|
int
|
期望采样的点数量,默认值为2000 |
2000
|
device
|
计算设备,可选"CPU:0"或"CUDA:1"等,默认使用CPU |
'CPU:0'
|
返回:
| 类型 | 描述 |
|---|---|
ndarray
|
采样点的索引数组,形状为[n_sample]的numpy数组,元素为原始点云的索引值 |
引发:
| 类型 | 描述 |
|---|---|
若设备指定无效(如CUDA不可用时指定"CUDA
|
1"),会抛出设备初始化错误 |
fill_hole_with_center(mesh, boundaries, return_vf=False)
用中心点方式强制补洞
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
mesh
|
_type_
|
vedo.Mesh |
必需 |
boundaries
|
vedo.boundaries |
必需 | |
return_vf
|
是否返回补洞的mesh |
False
|
fix_component_by_meshlab(ms)
移除低质量的组件,如小的连通分量,移除网格中的浮动小组件(小面积不连通部分)。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
ms
|
pymeshlab.MeshSet 对象 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
|
pymeshlab.MeshSet 对象 |
fix_floater_by_meshlab(mesh, nbfaceratio=0.1, nonclosedonly=False)
移除网格中的浮动小组件(小面积不连通部分)。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
mesh
|
MeshSet
|
输入的网格模型。 |
必需 |
nbfaceratio
|
float
|
面积比率阈值,小于该比率的部分将被移除。 |
0.1
|
nonclosedonly
|
bool
|
是否仅移除非封闭部分。 |
False
|
返回:
| 类型 | 描述 |
|---|---|
Mesh
|
pymeshlab.MeshSet: 移除浮动小组件后的网格模型。 |
fix_invalid_by_meshlab(ms)
处理冗余元素,如合移除重复面和顶点等, 清理无效的几何结构,如折叠面、零面积面和未引用的顶点。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
ms
|
pymeshlab.MeshSet 对象 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
|
pymeshlab.MeshSet 对象 |
fix_topology_by_meshlab(ms)
修复拓扑问题,如 T 型顶点、非流形边和非流形顶点,并对齐不匹配的边界。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
ms
|
pymeshlab.MeshSet 对象 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
|
pymeshlab.MeshSet 对象 |
furthestsampling_jit(xyz, offset, new_offset)
使用并行批次处理的最远点采样算法实现
该方法将输入点云划分为多个批次,每个批次独立进行最远点采样。通过维护最小距离数组, 确保每次迭代选择距离已选点集最远的新点,实现高效采样。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
xyz
|
ndarray
|
输入点云坐标,形状为(N, 3)的C连续float32数组 |
必需 |
offset
|
ndarray
|
原始点云的分段偏移数组,表示每个批次的结束位置。例如[1000, 2000]表示两个批次 |
必需 |
new_offset
|
ndarray
|
采样后的分段偏移数组,表示每个批次的目标采样数。例如[200, 400]表示每批采200点 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
ndarray
|
np.ndarray: 采样点索引数组,形状为(total_samples,),其中total_samples = new_offset[-1] |
Notes
实现特点: - 使用Numba并行加速,支持多核并行处理不同批次 - 采用平方距离计算避免开方运算 - 每批次独立初始化距离数组,避免跨批次干扰 - 自动处理边界情况(空批次或零采样批次)
典型调用流程:
n_total = 10000 offset = np.array([1000, 2000, ..., 10000], dtype=np.int32) new_offset = np.array([200, 400, ..., 2000], dtype=np.int32) sampled_indices = furthestsampling_jit(xyz, offset, new_offset)
get_axis_rotation(axis, angle)
绕着指定轴获取3*3旋转矩阵
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
axis
|
list
|
轴向,[0,0,1] |
必需 |
angle
|
float
|
旋转角度,90.0 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
array
|
3*3旋转矩阵 |
get_gaussian_heatmap(points, keypoints, sigma=0.5, normalize=False)
生成高斯热图(仅支持单样本点云和关键点)
参数
points: 点云坐标,形状为 (N, 3) keypoints: 关键点坐标,形状为 (K, 3) sigma: 高斯标准差,控制热图扩散范围,小则精确定位,大则抗干扰强 normalize: 是否归一化每个关键点的热图(最大值为1)
返回
heatmap: 热图数组,形状为 (N, K)
get_obb_box(x_pts, z_pts, vertices)
给定任意2个轴向交点及顶点,返回定向包围框mesh Args: x_pts: x轴交点 z_pts: z轴交点 vertices: 所有顶点
返回:
| 类型 | 描述 |
|---|---|
Tuple[list, list, array]
|
包围框的顶点, 面片索引,3*3旋转矩阵 |
get_obb_box_max_min(x_pts, z_pts, z_max_pts, z_min_pts, x_max_pts, x_min_pts, y_max_pts, y_min_pts, center)
给定任意2个轴向交点及最大/最小点,返回定向包围框mesh
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
x_pts
|
array
|
x轴交点 |
必需 |
z_pts
|
array
|
z轴交点 |
必需 |
z_max_pts
|
array
|
最大z顶点 |
必需 |
z_min_pts
|
array
|
最小z顶点 |
必需 |
x_max_pts
|
array
|
最大x顶点 |
必需 |
x_min_pts
|
array
|
最小x顶点 |
必需 |
y_max_pts
|
array
|
最大y顶点 |
必需 |
y_min_pts
|
array
|
最小y顶点 |
必需 |
center
|
array
|
中心点 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
Tuple[list, list, array]
|
包围框的顶点, 面片索引,3*3旋转矩阵 |
get_pca_rotation(vertices)
通过pca分析顶点,获取3*3旋转矩阵,并应用到顶点;
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
vertices
|
array
|
三维顶点 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
array
|
应用旋转矩阵后的顶点 |
get_pca_transform(mesh)
将输入的顶点数据根据曲率及PCA分析得到的主成分向量,
并转换成4*4变换矩阵。
Notes
必须为底部非封闭的网格
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
mesh
|
Mesh
|
vedo网格对象 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
array
|
4*4 变换矩阵 |
harmonic_by_igl(v, f, map_vertices_to_circle=True)
谐波参数化后的2D网格
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
v
|
_type_
|
顶点 |
必需 |
f
|
_type_
|
面片 |
必需 |
map_vertices_to_circle
|
是否映射到圆形(正方形) |
True
|
返回:
| 类型 | 描述 |
|---|---|
|
uv,v_p: 创建参数化后的2D网格,3D坐标 |
Note:
```
# 创建空间索引
uv_kdtree = KDTree(uv)
# 初始化可视化系统
plt = Plotter(shape=(1, 2), axes=False, title="Interactive Parametrization")
# 创建网格对象
mesh_3d = Mesh([v, f]).cmap("jet", calculate_curvature(v, f)).lighting("glossy")
mesh_2d = Mesh([v_p, f]).wireframe(True).cmap("jet", calculate_curvature(v, f))
# 存储选中标记
markers_3d = []
markers_2d = []
def on_click(event):
if not event.actor or event.actor not in [mesh_2d, None]:
return
if not hasattr(event, 'picked3d') or event.picked3d is None:
return
try:
# 获取点击坐标
uv_click = np.array(event.picked3d[:2])
# 查找最近顶点
_, idx = uv_kdtree.query(uv_click)
v3d = v[idx]
uv_point = uv[idx] # 获取对应2D坐标
# 创建3D标记(使用球体)
marker_3d = Sphere(v3d, r=0.1, c='cyan', res=12)
markers_3d.append(marker_3d)
# 创建2D标记(使用大号点)
marker_2d = Point(uv_point, c='magenta', r=10, alpha=0.8)
markers_2d.append(marker_2d)
# 更新视图
plt.at(0).add(marker_3d)
plt.at(1).add(marker_2d)
plt.render()
except Exception as e:
log.info(f"Error processing click: {str(e)}")
plt.at(0).show(mesh_3d, "3D Visualization", viewup="z")
plt.at(1).show(mesh_2d, "2D Parametrization").add_callback('mouse_click', on_click)
plt.interactive().close()
```
hole_filling_by_Radial(boundary_coords)
参考
[https://www.cnblogs.com/shushen/p/5759679.html]
实现的最小角度法补洞法;
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
boundary_coords
|
_type_
|
有序边界顶点 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
|
v,f: 修补后的曲面 |
Note
# 创建带孔洞的简单网格
s = vedo.load(r"J10166160052_16.obj")
# 假设边界点即网格边界点
boundary =vedo.Spline((s.boundaries().join(reset=True).vertices),res=100)
# 通过边界点进行补洞
filled_mesh =vedo.Mesh(hole_filling(boundary.vertices))
# 渲染补洞后的曲面
vedo.show([filled_mesh,boundary,s.alpha(0.8)], bg='white').close()
isotropic_remeshing_by_acvd(vedo_mesh, target_num=10000, clean=True)
对给定的 vedo 网格进行均质化处理,使其达到指定的目标面数。
该函数使用 pyacvd 库中的 Clustering 类对输入的 vedo 网格进行处理。 如果网格的顶点数小于等于目标面数,会先对网格进行细分,然后进行聚类操作, 最终生成一个面数接近目标面数的均质化网格。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
vedo_mesh
|
Mesh
|
输入的 vedo 网格对象,需要进行均质化处理的网格。 |
必需 |
target_num
|
int
|
目标面数,即经过处理后网格的面数接近该值。 默认为 10000。 |
10000
|
clean
|
去除均匀化错误的点 |
True
|
返回:
| 类型 | 描述 |
|---|---|
|
vedo.Mesh: 经过均质化处理后的 vedo 网格对象,其面数接近目标面数。 |
Notes
该函数依赖于 pyacvd 和 pyvista 库,使用前请确保这些库已正确安装。
isotropic_remeshing_by_meshlab(mesh, target_edge_length=0.5, iterations=1)
使用 PyMeshLab 实现网格均匀化。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
mesh
|
输入的网格对象 (pymeshlab.MeshSet)。 |
必需 | |
target_edge_length
|
目标边长比例 %。 |
0.5
|
|
iterations
|
迭代次数,默认为 1。 |
1
|
返回:
| 类型 | 描述 |
|---|---|
Mesh
|
均匀化后的网格对象。 |
labels2colors(labels)
将labels转换成颜色标签 Args: labels: numpy类型,形状(N)对应顶点的标签;
返回:
| 类型 | 描述 |
|---|---|
|
RGBA颜色标签; |
labels_mapping(old_vertices, old_faces, new_vertices, old_labels, fast=True)
将原始网格的标签属性精确映射到新网格
参数
old_mesh(vedo) : 原始网格对象 new_mesh(vedo): 重网格化后的新网格对象 old_labels (np.ndarray): 原始顶点标签数组,形状为 (N,)
返回
new_labels (np.ndarray): 映射后的新顶点标签数组,形状为 (M,)
line_project_mesh(v, f, loop_points, gen_new_edge=False)
将输入的3D点环投影到网格表面,根据参数决定是生成新的切割边还是仅提取投影轮廓。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
v
|
ndarray
|
网格顶点数组,形状为(N, 3)的浮点数组。 |
必需 |
f
|
ndarray
|
网格面索引数组,形状为(M, 3)的整数数组。 |
必需 |
loop_points
|
iterable
|
3D点列表/数组,定义要投影到网格上的环状路径。 |
必需 |
gen_new_edge
|
bool
|
是否生成新切割边。默认为True。 True: 在网格上生成新边并分割网格 False: 仅提取投影轮廓 |
False
|
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
tuple |
包含四个元素的元组: - res_pts (list): 投影轮廓的3D点列表,每个点为[x, y, z] - res_pts_idx (list): 新生成边的顶点索引列表(仅当gen_new_edge=True时有效) - res_v (np.ndarray): 处理后网格顶点数组(仅当gen_new_edge=True时返回新网格) - res_f (np.ndarray): 处理后网格面索引数组(仅当gen_new_edge=True时返回新网格) |
mesh2sdf(v, f, size=64)
体素化网格,该函数适用于非水密网格(带孔的网格)、自相交网格、具有非流形几何体的网格以及具有方向不一致的面的网格。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
v
|
array - like
|
网格的顶点数组。 |
必需 |
f
|
array - like
|
网格的面数组。 |
必需 |
size
|
int
|
体素化的大小,默认为 64。 |
64
|
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
array |
体素化后的数组。 |
引发:
| 类型 | 描述 |
|---|---|
ImportError
|
如果未安装 'mesh-to-sdf' 库,会提示安装。 |
mesh_uv_wrap(mesh)
对3D网格进行UV展开处理,使用xatlas库生成优化的UV坐标。
该函数接收一个trimesh网格或场景对象,将其转换为单个网格后, 使用xatlas算法进行参数化处理以生成UV坐标,最终返回带有UV信息的网格。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
mesh
|
Trimesh or Scene or str
|
输入的3D网格或mesh路径或场景对象。 如果是场景对象,会先合并为单个网格。 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
|
trimesh.Trimesh: 带有生成的UV坐标的网格对象,顶点和面可能经过重新索引。 |
引发:
| 类型 | 描述 |
|---|---|
ValueError
|
当输入网格的面数超过500,000,000时抛出,不支持过大的网格处理。 |
Note
处理过程中会使用xatlas.parametrize()进行UV展开,这可能会重新组织顶点和 faces索引。 生成的UV坐标会存储在网格的visual.uv属性中,可用于纹理映射等后续处理。
normal2color(normal)
将normal转换成颜色 Args: normal: 网格的法线
返回:
| 类型 | 描述 |
|---|---|
|
(0-255)颜色 |
resample_mesh(vertices, faces, density=1, num_samples=None)
在由顶点和面定义的网格表面上进行点云重采样。
- 密度模式:根据单位面片面积自动计算总采样数
- 指定数量模式:直接指定需要采样的总点数
该函数使用向量化操作高效地在网格表面进行均匀采样,采样密度由单位面积点数决定。 采样策略基于重心坐标系,采用分层随机抽样方法。
注意: 零面积三角形会被自动跳过,因为不会分配采样点。
参考实现: https://chrischoy.github.io/research/barycentric-coordinate-for-mesh-sampling/
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
vertices
|
ndarray
|
网格顶点数组,形状为(V, 3),V表示顶点数量 |
必需 |
faces
|
ndarray
|
三角形面片索引数组,形状为(F, 3),数据类型应为整数 |
必需 |
density
|
(float, 可选)
|
每单位面积的采样点数,默认为1 |
1
|
num_samples
|
(int, 可选)
|
指定总采样点数,若提供则忽略density参数 |
None
|
返回:
| 类型 | 描述 |
|---|---|
|
numpy.ndarray: 重采样后的点云数组,形状为(N, 3),N为总采样点数 |
Notes
采样点生成公式(重心坐标系): P = (1 - √r₁)A + √r₁(1 - r₂)B + √r₁ r₂ C 其中: - r₁, r₂ ∈ [0, 1) 为随机数 - A, B, C 为三角形顶点 - 该公式可确保在三角形表面均匀采样
算法流程: 1. 计算每个面的面积并分配采样点数 2. 通过随机舍入处理总点数误差 3. 使用向量化操作批量生成采样点
References
[1] Barycentric coordinate system - https://en.wikipedia.org/wiki/Barycentric_coordinate_system
restore_transform(vertices, transform)
根据提供的顶点及矩阵,进行逆变换(还原应用矩阵之前的状态)
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
vertices
|
array
|
顶点 |
必需 |
transform
|
array
|
4*4变换矩阵 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
array
|
还原后的顶点坐标 |
sample_sdf_mesh(v, f, number_of_points=200000)
在曲面附近不均匀地采样 SDF 点,该函数适用于非水密网格(带孔的网格)、自相交网格、具有非流形几何体的网格以及具有方向不一致的面的网格。 这是 DeepSDF 论文中提出和使用的方法。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
v
|
array - like
|
网格的顶点数组。 |
必需 |
f
|
array - like
|
网格的面数组。 |
必需 |
number_of_points
|
int
|
采样点的数量,默认为 200000。 |
200000
|
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
tuple |
包含采样点数组和对应的 SDF 值数组的元组。 |
引发:
| 类型 | 描述 |
|---|---|
ImportError
|
如果未安装 'mesh-to-sdf' 库,会提示安装。 |
sample_sharp_mesh(mesh, num=20000, angle_threshold=10.0)
从网格的尖锐边缘采样点云,支持上采样;(阈值为角度,单位:度) https://github.com/Tencent-Hunyuan/Hunyuan3D-2/blob/f8db63096c8282cb27354314d896feba5ba6ff8a/hy3dgen/shapegen/surface_loaders.py#L40 Args: mesh (trimesh.Trimesh): 输入网格 num (int): 采样点数,默认16384 angle_threshold (float): 尖锐度角度阈值(范围0~180度),值越大识别的尖锐边越“钝”,默认10度
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
samples |
ndarray
|
(num, 3) 采样点坐标 |
normals |
ndarray
|
(num, 3) 采样点法线 |
save_np_json(output_path, obj)
保存np形式的json
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
output_path
|
str
|
保存路径 |
必需 |
obj
|
保存对象 |
必需 |
show_gaussian_heatmap(vertices, heatmap, faces=None)
用于渲染三维顶点的高斯热力图 Args: vertices: 顶点,形状为 (N, 3) heatmap: 热图数组,形状为 (N, K) faces: 可选面片,如无,则按照点云渲染
simplify_by_meshlab(vertices, faces, max_facenum=30000)
通过二次边折叠算法减少网格中的面数,简化模型。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
mesh
|
MeshSet
|
输入的网格模型。 |
必需 |
max_facenum
|
int
|
简化后的目标最大面数,默认为 200000。 |
30000
|
返回:
| 类型 | 描述 |
|---|---|
Mesh
|
pymeshlab.MeshSet: 简化后的网格模型。 |
subdivide_loop_by_trimesh(vertices, faces, iterations=5, max_face_num=100000, face_mask=None)
对给定的顶点和面片进行 Loop 细分。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
vertices
|
array - like
|
输入的顶点数组,形状为 (n, 3),其中 n 是顶点数量。 |
必需 |
faces
|
array - like
|
输入的面片数组,形状为 (m, 3),其中 m 是面片数量。 |
必需 |
iterations
|
int
|
细分的迭代次数,默认为 5。 |
5
|
max_face_num
|
int
|
细分过程中允许的最大面片数量,达到此数量时停止细分,默认为 100000。 |
100000
|
face_mask
|
array - like
|
面片掩码数组,用于指定哪些面片需要进行细分,默认为 None。 |
None
|
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
tuple |
包含细分后的顶点数组、细分后的面片数组和面片掩码数组的元组。 |
Notes
以下是一个示例代码,展示了如何使用该函数:
# 1. 获取每个点的最近表面点及对应面
face_indices = set()
kdtree = cKDTree(mesh.vertices)
for p in pts:
# 查找半径2mm内的顶点
vertex_indices = kdtree.query_ball_point(p, r=1.0)
for v_idx in vertex_indices:
# 获取包含这些顶点的面片
faces = mesh.vertex_faces[v_idx]
faces = faces[faces != -1] # 去除无效索引
face_indices.update(faces.tolist())
face_indices = np.array([[i] for i in list(face_indices)])
new_vertices, new_face, _ = subdivide_loop(v, f, face_mask=face_indices)
vertex_labels_to_face_labels(faces, vertex_labels)
将三角网格的顶点标签转换成面片标签,存在一个面片,多个属性,则获取出现最多的属性。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
faces
|
Union[array, list]
|
三角网格面片索引 |
必需 |
vertex_labels
|
Union[array, list]
|
顶点标签 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
array
|
面片属性 |
voxel2array(grid_index_array, voxel_size=32)
将 voxel_grid_index 数组转换为固定大小的三维数组。
该函数接收一个形状为 (N, 3) 的 voxel_grid_index 数组, 并将其转换为形状为 (voxel_size, voxel_size, voxel_size) 的三维数组。 其中,原 voxel_grid_index 数组中每个元素代表三维空间中的一个网格索引, 在转换后的三维数组中对应位置的值会被设为 1,其余位置为 0。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
grid_index_array
|
ndarray
|
形状为 (N, 3) 的数组, 通常从 open3d 的 o3d.voxel_grid.get_voxels() 方法获取, 表示三维空间中每个体素的网格索引。 |
必需 |
voxel_size
|
int
|
转换后三维数组的边长,默认为 32。 |
32
|
返回:
| 类型 | 描述 |
|---|---|
|
numpy.ndarray: 形状为 (voxel_size, voxel_size, voxel_size) 的三维数组, 其中原 voxel_grid_index 数组对应的网格索引位置值为 1,其余为 0。 |
Example
# 获取 grid_index_array
voxel_list = voxel_grid.get_voxels()
grid_index_array = list(map(lambda x: x.grid_index, voxel_list))
grid_index_array = np.array(grid_index_array)
voxel_grid_array = voxel2array(grid_index_array, voxel_size=32)
grid_index_array = array2voxel(voxel_grid_array)
pointcloud_array = grid_index_array # 0.03125 是体素大小
pc = o3d.geometry.PointCloud()
pc.points = o3d.utility.Vector3dVector(pointcloud_array)
o3d_voxel = o3d.geometry.VoxelGrid.create_from_point_cloud(pc, voxel_size=0.05)
o3d.visualization.draw_geometries([pcd, cc, o3d_voxel])
专注于牙颌mesh的特殊实现
convert_fdi2idx(labels)
将口腔牙列的FDI编号(11-18,21-28/31-38,41-48)转换为(1-16),只支持单颌: 上颌: - 右上(11-18) → 1-8 - 左上(21-28) → 9-16
下颌: - 左下(31-38) → 1-8 - 右下(41-48) → 9-16 - 0或小于0 → 0
1 9
2 10
3 11
4 12
5 13
6 14
7 15 8 16
convert_labels2color(data)
将牙齿标签转换成RGBA颜色
Notes
只支持以下标签类型:
upper_dict = [0, 18, 17, 16, 15, 14, 13, 12, 11, 21, 22, 23, 24, 25, 26, 27, 28]
lower_dict = [0, 48, 47, 46, 45, 44, 43, 42, 41, 31, 32, 33, 34, 35, 36, 37, 38]
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
data
|
Union[array, list]
|
属性 |
必需 |
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
colors |
list
|
对应属性的RGBA类型颜色 |
cut_crown_with_meshlib(mesh, margin_points)
使用边缘点分割牙冠网格模型,返回保留部分和移除部分。
该函数通过以下步骤实现牙冠分割: 1. 在输入网格中定位距离边缘线最近的连通区域 2. 使用边缘线切割该区域 3. 根据边界距离验证切割结果 4. 合并剩余网格组件
参数: mesh: vedo.Mesh对象,表示待分割的牙冠网格模型 margin_points: np.ndarray数组,形状为(N,3)的边缘点集
返回: Tuple[vedo.Mesh, vedo.Mesh]: 第一个Mesh为保留部分(牙冠主体) 第二个Mesh为移除部分(牙龈区域)
异常: 当边缘点与网格的最小距离超过1mm时触发断言错误
cut_mesh_point_loop_crow(mesh, pts, error_show=True, invert=True)
实现的基于线的牙齿冠分割;
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
mesh
|
_type_
|
待切割网格 |
必需 |
pts
|
Points / Line
|
切割线 |
必需 |
error_show
|
bool
|
裁剪失败是否进行渲染. Defaults to True. |
True
|
invert
|
bool
|
是否取反; |
True
|
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
_type_ |
切割后的网格 |
cut_with_ribbon(mesh, pts)
使用点序列切割网格
参数: pts: 切割点序列 (k, 3)
返回: new_v: 切割后顶点 new_f: 切割后面
deform_and_merge_mesh(mesh_path, base_mesh_path, ref_direction=np.array([0, 0, -1]), angle_threshold=30, boundary_samples=200, non_boundary_samples=500, boundary_radius=1.0, seed=1024)
将网格变形并与基础网格合并,用于将AI生成闭合冠裁剪并拟合到基座上;
该函数: 1. 基于参考方向的角度阈值处理输入网格 2. 识别边界区域 3. 生成变形控制点 4. 将边界区域变形以匹配基础网格 5. 将变形后的网格与基础网格合并
Notes:
''' # 自定义参考方向向量 sm = SindreMesh(r"J10177170088_UpperJaw_gen.ply") custom_direction = np.array(sm.vertices[42734] - sm.vertices[48221])
result_mesh = deform_and_merge_mesh(
mesh_path=r"J10177170088_UpperJaw_gen.ply",
base_mesh_path=r"17.ply",
ref_direction=custom_direction,
angle_threshold=30,
boundary_samples=200,
non_boundary_samples=500
)
result_mesh.write("merged_result.ply")
show(result_mesh, axes=1).close()
'''
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
mesh_path
|
str
|
主网格PLY文件路径 |
必需 |
base_mesh_path
|
str
|
基础网格PLY文件路径 |
必需 |
ref_direction
|
ndarray
|
参考方向向量 (默认 [0,0,1]) |
array([0, 0, -1])
|
angle_threshold
|
float
|
用于面片过滤的角度阈值 (度) |
30
|
boundary_samples
|
int
|
边界点采样数量 |
200
|
non_boundary_samples
|
int
|
非边界点采样数量 |
500
|
boundary_radius
|
float
|
边界区域识别半径 |
1.0
|
seed
|
int
|
随机种子 (确保结果可重现) |
1024
|
Returns:
vedo.Mesh: 合并并清理后的网格
get_mesh_side_area(target_mesh, template_center)
获取邻牙网格中面向模板一侧的所有面片,并计算其总面积 (注:面向模板的面片指面片法向量与"邻牙中心指向模板中心"的方向夹角小于60°的面片)
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
target_mesh
|
(tirmesh) 邻牙的网格模型(包含面片信息、法向量等属性) |
必需 | |
template_center
|
ndarray
|
生成模板的三维中心坐标 |
必需 |
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
area |
面向模板一侧的所有面片总面积 |
|
mask |
布尔数组,标记哪些面片属于面向模板的一侧(True表示是) |
|
face_indices |
面向模板一侧的面片索引列表 |
示例:
collision_side_area, collision_side_faces, collision_side_faces = get_collision_side_faces(mesh1, center_mass) sub_mesh = mesh1.submesh([collision_side_faces])[0] mesh1.visual.face_colors = [100, 100, 100, 100] # 灰色半透明 mesh1.visual.face_colors[collision_side_faces] = [255, 0, 0, 255] # 红色不透明 scene = trimesh.Scene() scene.add_geometry(mesh1) scene.add_geometry(sub_mesh) scene.show()
labels2colors_freeze(labels)
点云标签的颜色映射;
subdivide_with_pts(v, f, line_pts, r=0.15, iterations=3, method='mid')
对给定的网格和线点集进行局部细分。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
v
|
array - like
|
输入网格的顶点数组。 |
必需 |
f
|
array - like
|
输入网格的面数组。 |
必需 |
line_pts
|
array - like
|
线的点集数组。 |
必需 |
r
|
float
|
查找线点附近顶点的半径,默认为 0.15. |
0.15
|
method
|
str
|
细分方法,可选值为 "mid"(中点细分)或其他值(对应 ls3_loop 细分),默认为 "mid"。 |
'mid'
|
返回:
| 类型 | 描述 |
|---|---|
|
|
|
Notes
# 闭合线可能在曲面上,曲面内,曲面外
line = Line(pts)
mesh = isotropic_remeshing_by_acvd(mesh)
v, f = np.array(mesh.vertices), np.array(mesh.cells)
new_vertices, new_face = subdivide_with_pts(v, f, pts)
show([(Mesh([new_vertices, new_face]).c("green"), Line(pts, lw = 2, c = "red")),
(Mesh([v, f]).c("pink"), Line(pts, lw = 2, c = "red"))], N = 2).close()
transform_crown(near_mesh, jaw_mesh)
调整单冠的轴向
Tip
1.通过连通域分割两个邻牙;
2.以邻牙质心为确定x轴;
3.通过找对颌最近的点确定z轴方向;如果z轴方向上有mesh,则保持原样,否则将z轴取反向;
4.输出调整后的牙冠
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
near_mesh
|
Mesh
|
两个邻牙组成的mesh |
必需 |
jaw_mesh
|
Mesh
|
两个邻牙的对颌 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
Mesh
|
变换后的单冠mesh |
SindreMesh
三维网格中转类,假设都是三角面片
center
cached
property
计算网格的加权质心(基于面片面积加权)。
返回:
| 类型 | 描述 |
|---|---|
ndarray
|
np.ndarray: 加权质心坐标,形状为 (3,)。 |
Notes
使用三角形面片面积作为权重,对三角形质心坐标进行加权平均。 该结果等价于网格的几何中心。
faces_area
cached
property
计算每个三角形面片的面积。
Notes
使用叉乘公式计算面积: 面积 = 0.5 * ||(v1 - v0) × (v2 - v0)||
faces_barycentre
cached
property
每个三角形的中心(重心 [1/3,1/3,1/3])
faces_vertices
cached
property
将面片索引用顶点来表示
get_adj_list
cached
property
邻接表属性
get_adj_matrix
cached
property
基于去重边构建邻接矩阵
get_edges
cached
property
未去重边缘属性
nfaces
cached
property
获取顶点数量
npoints
cached
property
获取顶点数量
to_dict
property
将属性转换成python字典
to_json
property
转换成json
to_meshlab
property
转换成meshlab
to_open3d
property
转换成open3d
to_open3d_t
property
转换成open3d_t
to_trimesh
property
转换成trimesh
to_vedo
property
转换成vedo
to_vedo_pointcloud
property
转换成vedo点云
__repr__()
网格质量检测
apply_inv_transform(mat)
对顶点应用4x4/3x3变换矩阵进行逆变换(支持非正交矩阵)
apply_transform(mat)
对顶点应用4x4/3x3变换矩阵(支持非正交矩阵)
apply_transform_normals(mat)
处理顶点法线的变换(支持非均匀缩放和反射变换)---废弃,在复杂非正定矩阵,重新计算法线比变换更快,更加准确
check()
检测数据完整性,正常返回True
clean()
删除退化面片,删除孤立顶点
clone()
快速克隆当前网格对象
compute_normals(force=False)
计算顶点法线及面片法线.force代表是否强制重新计算
cut_mesh(loop_points, get_bigger_part=False, smooth_boundary=False)
将输入的3D点环投影到网格表面,根据参数决定是生成新的切割边还是仅提取投影轮廓。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
loop_points
|
iterable
|
3D点列表/数组,定义要投影到网格上的环状路径。 |
必需 |
get_bigger_part
|
bool
|
选择面积大的mesh; |
False
|
smooth_boundary
|
bool
|
优化边界; |
False
|
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
sindremesh |
裁剪后的sindremesh |
decimate(n=10000, method=0)
网格下采样到指定目标顶点数,支持4种简化算法,自动传递顶点属性(标签/曲率)。
核心逻辑:通过面塌陷(Edge Collapse)或空间分箱实现简化,确保简化后网格的顶点属性(标签、曲率) 按合理策略聚合(如平均),避免属性丢失。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
n
|
目标顶点数(int),需满足 3 ≤ n ≤ 原始顶点数(过小会导致网格拓扑无效)。 注意:method=2(Binned)无法精确控制顶点数,仅能通过分箱间接影响。 |
10000
|
|
method
|
简化算法选择(int,0-3): 0: vedo.decimate → 基于VTK QuadricDecimation,速度中,精度高(优先推荐); 1: vedo.decimate_pro → 基于VTK DecimatePro,速度中,精度中,支持强拓扑控制; 2: vedo.decimate_binned → 基于VTK BinnedDecimation,速度高,精度低,无法指定n; 3: 3: fast-simplification → 基于快速边折叠,速度最高,精度高,支持属性精确聚合,建议百万顶点上调用。 |
0
|
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
Self |
简化后的网格对象(更新自身的顶点、面、顶点标签、顶点曲率)。 |
fix_mesh()
修复基本mesh错误
get_boundary(return_points=True, max_boundary=False)
获取非水密网格的边界环(可能有多个环);
Method: 1. 获取所有的边(未去重),并统计每条边出现的次数。在三角网格中,内部边会被两个三角形共享,而边界边只被一个三角形使用。 2. 筛选出只出现一次的边,这些边就是边界边。 3. 将边界边连接成有序的环(或多个环)。通过构建边界边的图,然后进行深度优先搜索或广度优先搜索来连接相邻的边。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
return_points
|
bool
|
True返回顶点坐标,False返回顶点索引 |
True
|
max_boundary
|
bool
|
True时只返回最大的边界环(按顶点数量) |
False
|
Return: list: 边界环列表,每个环是顶点索引的有序序列(闭合环,首尾顶点相同),当max_boundary=True,单个边界环数组
get_boundary_by_normal_angle(angle_threshold=30, max_boundary=True)
通过相邻三角面法线夹角识别特征边界环
Note
- 计算所有三角面的归一化法向量
- 遍历网格所有边,筛选出相邻两面法线夹角大于阈值的边(特征边)
- 将特征边连接成有序封闭环
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
self
|
必须为水密网格; |
必需 | |
angle_threshold
|
法线夹角阈值(度),默认30度; |
30
|
|
max_boundary
|
是否仅返回最长边界环,默认True; |
True
|
返回:
| 类型 | 描述 |
|---|---|
|
边界环顶点索引列表(若max_boundary=True则返回单个环) |
get_boundary_by_ref_normal_angle(ref_normal=[0, 0, -1], angle=30)
通过参考法线和角度阈值获取网格边界顶点
Note
将输入的参考法线转换为 numpy 数组 计算网格所有面的法线与参考法线的余弦相似度 筛选出与参考法线夹角小于阈值角度的面(余弦值大于阈值角度的余弦值) 对筛选出的面进行处理,提取并返回其边界顶点
Args:
self: 网格对象,需包含面法线 (face_normals)、顶点 (vertices) 和面 (faces) 属性;
ref_normal: 参考法线向量,默认值为 [0, 0, -1] 朝向-z方向;
angle: 角度阈值 (度),默认 30 度,用于筛选与参考法线夹角小于该值的面;
Returns:
边界顶点坐标;
get_color_mapping(value)
将向量映射为颜色,遵从vcg映射标准
get_curvature()
获取曲率
get_curvature_meshlab()
使用MeshLab获取更加精确曲率,自动处理非流形几何
get_faces_labels()
将顶点标签转换成面片标签 Returns:面片标签
get_near_idx(query_vertices)
获取最近索引
get_normalize(method='ball')
对顶点、曲率和颜色数据进行归一化处理
该方法支持两种归一化方式,可将顶点坐标、曲率值和颜色值 归一化到特定范围,便于后续处理和分析。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
method
|
str
|
归一化方法。可选值为"ball"或其他。 "ball"表示将顶点中心移至原点并缩放至单位球内; 其他值表示将顶点缩放到[0,1]范围。默认值为"ball"。 |
'ball'
|
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
dict |
包含归一化后的数据字典,键值对如下: - "vertices":归一化后的顶点坐标数组(已转换method参数为范围) - "normals": 法线(已转换为[-1,1]范围) - "curvature": 归一化后的曲率值数组(已转换为[-1,1]范围) - "colors": 归一化后的颜色值数组(已转换为[0,1]范围) |
get_texture(image_size=(512, 512), uv=None)
将颜色转换为纹理贴图, Mesh([v, f]).texture(write_path,uv)
get_unused_vertices()
获取未使用顶点的索引
get_uv(return_circle=False)
cached
获取uv映射 与顶点一致(npoinst,2)
homogenize(n=10000)
均匀化网格到指定点数,采用聚类
load(load_path)
读取(.sm .smesh)文件
print_o3d()
使用open3d网格质量检测
remove_degenerate_faces()
检测并删除退化面片
remove_faces_by_vertex_indices(vertex_indices)
删除所有包含指定顶点索引的面片
rotate_xyz(angles_xyz, return_mat=False)
按照给定xyz角度列表进行xyz对应旋转
sample(density=1, num_samples=None)
网格表面上进行点云重采样 Args: density (float, 可选): 每单位面积的采样点数,默认为1 num_samples (int, 可选): 指定总采样点数N,若提供则忽略density参数
返回:
| 类型 | 描述 |
|---|---|
|
numpy.ndarray: 重采样后的点云数组,形状为(N, 3),N为总采样点数 |
save(write_path)
保存mesh,pickle(.sm .smesh),其他由vedo支持
scale_xyz(dxdydz)
缩放xyz指定量,支持输入3个向量和1个向量
set_faces_labels(faces_labels)
将面片labels转换为顶点labels,并自动渲染颜色
set_vertex_labels(vertex_labels)
设置顶点labels,并自动渲染颜色
shift_xyz(dxdydz)
平移xyz指定量,支持输入3个向量和1个向量
show(show_append=[], labels=None, exclude_list=[0], create_axes=True, return_obj=False, by_open3d=False)
渲染并展示网格数据,支持根据标签着色、添加标记及坐标系显示。
Args: show_append (list):需要与主网格一起渲染的额外vedo对象列表 labels (numpy.ndarray, 可选):网格顶点的标签数组。若提供,将: - 根据标签值为顶点分配颜色 - 为每个不在排除列表中的标签添加标记 exclude_list (list, 可选):默认值为[0],指定不显示标记的标签列表 create_axes (bool):是否强制显示世界坐标系,默认为True return_obj (bool):是否返回vedo显示对象列表而非直接渲染,默认为False by_open3d (bool):是否使用Open3D引擎进行渲染,默认为False(使用vedo引擎)
Returns: 若return_vedo_obj为True,返回包含所有待显示对象的列表; 否则无返回值,直接弹出渲染窗口。
split_component(return_largest=True)
将网格按照连通分量分割,并返回最大和其余连通分量的顶点索引
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
tuple |
包含三个数组的元组 - 第一个元素: 连通分量数量 - 第二个元素: 最大连通分量的节点索引 - 第三个元素: 剩余部分的节点索引(即非最大连通分量的所有节点) |
subdivison(face_mask, iterations=3, method='mid')
局部细分
texture2colors(image_path='texture_uv.png', uv=None)
将纹理贴图转换成顶点颜色
to_pytorch3d(device='cpu')
转换成pytorch3d形式
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
mesh |
pytorch3d类型mesh |
to_torch(device='cpu')
将顶点&面片转换成torch形式
返回:
| 类型 | 描述 |
|---|---|
|
vertices,faces,vertex_normals,vertex_colors: 顶点,面片,法线,颜色(没有则为None) |
update_geometry(new_vertices, new_faces=None)
更新网格的几何结构(顶点和面片),并通过最近邻算法将原有的顶点属性映射到新顶点上。
适用于在保持网格拓扑结构基本不变的情况下,对网格进行变形,细化,简化的场景。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
new_vertices
|
形状为(N,3)的浮点型数组,表示新的顶点坐标 |
必需 | |
new_faces
|
可选参数,形状为(M,3)的整数型数组,表示新的面片索引 |
None
|
notes
- 当新顶点数量与原顶点数量不同时,原顶点属性会根据最近邻关系进行映射
- 如果未提供新的面片信息,函数会尝试根据旧面片和顶点映射关系重建面片
matrix3d_by_vedo
Bases: Plotter
Generate a rendering window with slicing planes for the input Volume.
__init__(data, cmaps=('gist_ncar_r', 'hot_r', 'bone', 'bone_r', 'jet', 'Spectral_r'), clamp=True, show_histo=True, show_icon=True, draggable=False, at=0, **kwargs)
Generate a rendering window with slicing planes for the input Volume.
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
cmaps
|
(list) list of color maps names to cycle when clicking button |
必需 | |
clamp
|
(bool) clamp scalar range to reduce the effect of tails in color mapping |
必需 | |
use_slider3d
|
(bool) show sliders attached along the axes |
必需 | |
show_histo
|
(bool) show histogram on bottom left |
必需 | |
show_icon
|
(bool) show a small 3D rendering icon of the volume |
必需 | |
draggable
|
(bool) make the 3D icon draggable |
必需 | |
at
|
(int) subwindow number to plot to |
必需 | |
**kwargs
|
(dict) keyword arguments to pass to Plotter. |
必需 |
示例:
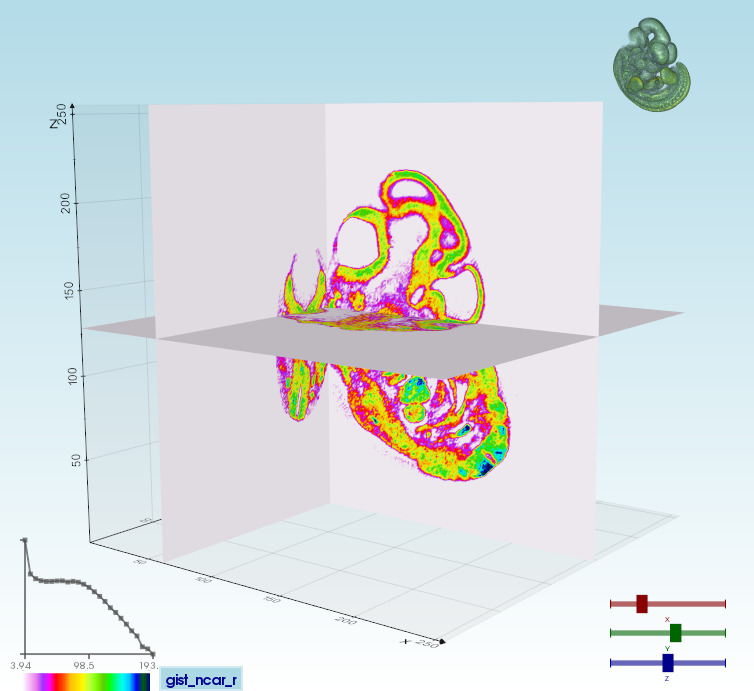
show_matrix_by_vedo(data)
用vedo渲染矩阵
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
data
|
ndarray
|
输入的2d/3d数组; |
必需 |
神经网络API
AdaIN
Bases: Module
Adaptive Instance Normalization (AdaIN) layer.
将隐向量中编码的风格迁移到输入张量中。 首先对输入张量进行归一化处理("白化"),然后使用从隐向量生成的参数 进行反归一化,从而将风格信息编码到输入张量中。
原始论文: https://arxiv.org/abs/1703.06868 基于实现: https://github.com/SiskonEmilia/StyleGAN-PyTorch
Attributes: norm: 归一化层,用于对输入图像进行"白化"处理。 默认为InstanceNorm2d,也可以是其他归一化模块。
CrossAttentionDecoder
Bases: Module
交叉注意力解码器模块,用于通过潜在变量(Latents)增强查询(Queries)的特征表示。
该模块将输入查询通过傅里叶嵌入编码后,与潜在变量进行交叉注意力交互,最终生成目标输出(如分类概率)。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
num_latents
|
int
|
潜在变量的数量(即每个样本的上下文标记数)。 |
必需 |
out_channels
|
int
|
输出通道数(如分类类别数)。 |
必需 |
fourier_embedder
|
FourierEmbedder
|
傅里叶特征嵌入器,用于编码输入查询。 |
必需 |
width
|
int
|
特征投影后的维度(注意力模块的隐藏层宽度)。 |
必需 |
heads
|
int
|
注意力头的数量。 |
必需 |
qkv_bias
|
bool
|
是否在 Q/K/V 投影中添加偏置项,默认为 True。 |
True
|
qk_norm
|
bool
|
是否对 Q/K 进行层归一化,默认为 False。 |
False
|
属性:
| 名称 | 类型 | 描述 |
|---|---|---|
query_proj |
Linear
|
将傅里叶嵌入后的查询投影到指定宽度的线性层。 |
cross_attn_decoder |
ResidualCrossAttentionBlock
|
残差交叉注意力块。 |
ln_post |
LayerNorm
|
输出前的层归一化。 |
output_proj |
Linear
|
最终输出投影层。 |
Shape
- 输入 queries: (bs, num_queries, query_dim)
- 输入 latents: (bs, num_latents, latent_dim)
- 输出 occ: (bs, num_queries, out_channels)
forward(queries, latents)
前向传播流程:傅里叶嵌入 -> 投影 -> 交叉注意力 -> 归一化 -> 输出投影。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
queries
|
FloatTensor
|
输入查询张量,形状 (bs, num_queries, query_dim) |
必需 |
latents
|
FloatTensor
|
潜在变量张量,形状 (bs, num_latents, latent_dim) |
必需 |
返回:
| 类型 | 描述 |
|---|---|
FloatTensor
|
torch.FloatTensor: 输出张量,形状 (bs, num_queries, out_channels) |
DropPath
Bases: Module
随机深度(Stochastic Depth)模块,用于在残差块的主路径上随机丢弃样本路径。
该模块通过以概率 drop_prob 将输入张量置零(跳过当前残差块),同时根据 scale_by_keep
决定是否缩放输出值以保持期望不变。常用于正则化深层网络(如ResNet、Vision Transformer)。
Notes:
它与作者为 EfficientNet 等网络创建的 DropConnect 实现类似,但原来的名称具有误导性,
因为 “Drop Connect” 在另一篇论文中是一种不同形式的丢弃技术。
作者选择将层和参数名称更改为 “drop path”,
而不是将 DropConnect 作为层名并使用 “survival rate(生存概率)” 作为参数。
[https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956]
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
drop_prob
|
float
|
路径丢弃概率,取值范围 [0, 1),默认为 0(不丢弃)。 |
0.0
|
scale_by_keep
|
bool
|
若为 True,保留路径时会进行缩放补偿(除以 |
True
|
属性:
| 名称 | 类型 | 描述 |
|---|---|---|
drop_prob |
float
|
继承自 Args 的路径丢弃概率。 |
scale_by_keep |
bool
|
继承自 Args 的缩放开关。 |
Example
x = torch.randn(2, 3, 16, 16) drop_path = DropPath(drop_prob=0.2) train_output = drop_path(x) # 训练时随机丢弃路径 drop_path.eval() eval_output = drop_path(x) # 推理时直接返回原值
__init__(drop_prob=0.0, scale_by_keep=True)
初始化方法,配置丢弃概率和缩放开关
extra_repr()
用于打印模块的附加信息
forward(x)
前向传播,训练时随机丢弃路径,推理时直接返回输入。
具体实现逻辑:
1. 若 drop_prob=0 或处于推理模式,直接返回输入。
2. 生成与输入张量 x 的 batch 维度对齐的随机二值掩码。
3. 根据 scale_by_keep 决定是否对保留路径的样本进行缩放补偿。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
x
|
Tensor
|
输入张量,形状为 [batch_size, ...] |
必需 |
返回:
| 类型 | 描述 |
|---|---|
Tensor
|
torch.Tensor: 输出张量,训练时可能被部分置零,形状与输入一致。 |
FourierEmbedder
Bases: Module
傅里叶变换(正弦/余弦位置)嵌入模块。给定形状为 [n_batch, ..., c_dim] 的输入张量 `x`,
它将 `x[..., i]` 的每个特征维度转换为如下形式:
[
sin(x[..., i]),
sin(f_1*x[..., i]),
sin(f_2*x[..., i]),
...
sin(f_N * x[..., i]),
cos(x[..., i]),
cos(f_1*x[..., i]),
cos(f_2*x[..., i]),
...
cos(f_N * x[..., i]),
x[..., i] # 仅当 include_input 为 True 时保留
]
其中 f_i 表示频率。
频率空间默认为 [0/num_freqs, 1/num_freqs, ..., (num_freqs-1)/num_freqs]。
若 `logspace` 为 True,则频率按对数空间排列:f_i = [2^(0/num_freqs), 2^(1/num_freqs), ..., 2^((num_freqs-1)/num_freqs)];
否则,频率在 [1.0, 2^(num_freqs-1)] 范围内线性均匀分布。
Args: num_freqs (int): 频率数量,默认为6;
logspace (bool): 是否使用对数空间频率。若为True,频率为 2^(i/num_freqs);否则线性间隔,默认为True;
input_dim (int): 输入维度,默认为3;
include_input (bool): 是否在输出中包含原始输入,默认为True;
include_pi (bool): 是否将频率乘以π,默认为True。
属性:
| 名称 | 类型 | 描述 |
|---|---|---|
frequencies |
Tensor
|
频率张量。若 |
out_dim |
int
|
嵌入后的维度。若 |
__init__(num_freqs=6, logspace=True, input_dim=3, include_input=True, include_pi=True)
初始化方法
forward(x)
前向传播
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
x
|
Tensor
|
输入张量,形状为 [..., dim] |
必需 |
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
embedding |
Tensor
|
嵌入后的张量,形状为 [..., dim * (num_freqs*2 + temp)], 其中 temp 为1(若包含输入)或0。 |
get_dims(input_dim)
计算输出维度
GEGLU
Bases: Module
GeGLU activation function.
Taken from 3DShape2VecSet, Zhang et al., SIGGRAPH23. https://github.com/1zb/3DShape2VecSet/blob/master/models_ae.py
MLP
Bases: Module
多层感知机(MLP)模块,包含扩展投影、激活函数、收缩投影和可选的 DropPath 正则化。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
width
|
int
|
输入特征维度。 |
必需 |
output_width
|
int
|
输出特征维度,默认为 None(与输入相同)。 |
None
|
drop_path_rate
|
float
|
DropPath 的路径丢弃概率,默认为 0.0(不启用)。 |
0.0
|
Shape
- 输入 x: (..., width)
- 输出: (..., output_width or width)
forward(x)
前向传播流程:扩展 -> 激活 -> 收缩 -> DropPath(若启用)
MultiheadAttention
Bases: Module
多头自注意力模块,包含 QKV 投影和注意力计算。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
n_ctx
|
int
|
上下文长度(序列长度)。 |
必需 |
width
|
int
|
输入/输出特征维度。 |
必需 |
heads
|
int
|
注意力头数量。 |
必需 |
qkv_bias
|
bool
|
是否在 QKV 投影中添加偏置项,默认为 True。 |
必需 |
norm_layer
|
Module
|
归一化层类型,默认为 |
LayerNorm
|
qk_norm
|
bool
|
是否对 Q/K 进行归一化,默认为 False。 |
False
|
drop_path_rate
|
float
|
DropPath 的丢弃概率,默认为 0.0(不启用)。 |
0.0
|
Shape
- 输入 x: (bs, n_ctx, width)
- 输出: (bs, n_ctx, width)
MultiheadCrossAttention
Bases: Module
多头交叉注意力模块,包含线性投影和注意力计算。
将输入 x 和 data 分别投影为 Q 和 K/V,并通过 QKVMultiheadCrossAttention 计算交叉注意力。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
width
|
int
|
输入/输出特征维度。 |
必需 |
heads
|
int
|
注意力头的数量。 |
必需 |
qkv_bias
|
bool
|
是否在 Q/K/V 投影中添加偏置项,默认为 True。 |
True
|
n_data
|
int
|
键值对数据的数量,默认为 None。 |
None
|
data_width
|
int
|
输入数据 |
None
|
norm_layer
|
Module
|
归一化层类型,默认为 |
LayerNorm
|
qk_norm
|
bool
|
是否对 Q/K 进行归一化,默认为 False。 |
False
|
Shape
- 输入 x: (bs, n_ctx, width)
- 输入 data: (bs, n_data, data_width)
- 输出: (bs, n_ctx, width)
QKVMultiheadAttention
Bases: Module
基于 QKV 拼接的多头自注意力计算模块。
将输入的拼接 QKV 张量分割为独立的 Q/K/V,并应用缩放点积注意力。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
heads
|
int
|
注意力头数量。 |
必需 |
n_ctx
|
int
|
上下文长度(序列长度)。 |
必需 |
width
|
int
|
输入特征维度,默认为 None。 |
None
|
qk_norm
|
bool
|
是否对 Q/K 进行归一化,默认为 False。 |
False
|
norm_layer
|
Module
|
归一化层类型,默认为 |
LayerNorm
|
Shape
- 输入 qkv: (bs, n_ctx, width * 3) # Q/K/V 拼接后的张量
- 输出: (bs, n_ctx, width)
QKVMultiheadCrossAttention
Bases: Module
基于查询(Query)、键值对(Key-Value)的多头交叉注意力计算模块。
通过将输入的 q 和 kv 分割为多头,应用缩放点积注意力(Scaled Dot-Product Attention),
并可选对 Q/K 进行归一化处理。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
heads
|
int
|
注意力头的数量。 |
必需 |
n_data
|
int
|
键值对数据的数量(上下文长度),默认为 None。 |
None
|
width
|
int
|
输入特征的维度,默认为 None。 |
None
|
qk_norm
|
bool
|
是否对 Q/K 进行层归一化,默认为 False。 |
False
|
norm_layer
|
Module
|
归一化层类型,默认为 |
LayerNorm
|
属性:
| 名称 | 类型 | 描述 |
|---|---|---|
heads |
int
|
继承自 Args 的注意力头数量。 |
q_norm |
Module
|
查询向量的归一化层(若启用 qk_norm)。 |
k_norm |
Module
|
键向量的归一化层(若启用 qk_norm)。 |
Shape
- 输入 q: (bs, n_ctx, width)
- 输入 kv: (bs, n_data, width * 2) # 包含键和值拼接后的张量
- 输出: (bs, n_ctx, width)
ResidualAttentionBlock
Bases: Module
残差自注意力块,包含多头自注意力和 MLP 子模块。
结构:LN -> Self-Attention -> Add -> LN -> MLP -> Add
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
n_ctx
|
int
|
上下文长度(序列长度)。 |
必需 |
width
|
int
|
输入特征维度。 |
必需 |
heads
|
int
|
注意力头数量。 |
必需 |
qkv_bias
|
bool
|
是否在 QKV 投影中添加偏置项,默认为 True。 |
True
|
norm_layer
|
Module
|
归一化层类型,默认为 |
LayerNorm
|
qk_norm
|
bool
|
是否对 Q/K 进行归一化,默认为 False。 |
False
|
drop_path_rate
|
float
|
DropPath 的丢弃概率,默认为 0.0。 |
0.0
|
Shape
- 输入 x: (bs, n_ctx, width)
- 输出: (bs, n_ctx, width)
ResidualCrossAttentionBlock
Bases: Module
残差交叉注意力块,包含多头交叉注意力和 MLP 子模块。
结构:LN -> Cross-Attention -> Add -> LN -> MLP -> Add
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
n_data
|
int
|
键值对数据的数量,默认为 None。 |
None
|
width
|
int
|
输入特征维度。 |
必需 |
heads
|
int
|
注意力头的数量。 |
必需 |
data_width
|
int
|
输入数据 |
None
|
qkv_bias
|
bool
|
是否在 Q/K/V 投影中添加偏置项,默认为 True。 |
True
|
norm_layer
|
Module
|
归一化层类型,默认为 |
LayerNorm
|
qk_norm
|
bool
|
是否对 Q/K 进行归一化,默认为 False。 |
False
|
Shape
- 输入 x: (bs, n_ctx, width)
- 输入 data: (bs, n_data, data_width)
- 输出: (bs, n_ctx, width)
Transformer
Bases: Module
Transformer 模型,由多层 ResidualAttentionBlock 堆叠而成。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
n_ctx
|
int
|
上下文长度(序列长度)。 |
必需 |
width
|
int
|
输入特征维度。 |
必需 |
layers
|
int
|
残差注意力块的层数。 |
必需 |
heads
|
int
|
注意力头数量。 |
必需 |
qkv_bias
|
bool
|
是否在 QKV 投影中添加偏置项,默认为 True。 |
True
|
norm_layer
|
Module
|
归一化层类型,默认为 |
LayerNorm
|
qk_norm
|
bool
|
是否对 Q/K 进行归一化,默认为 False。 |
False
|
drop_path_rate
|
float
|
DropPath 的丢弃概率,默认为 0.0。 |
0.0
|
Shape
- 输入 x: (bs, n_ctx, width)
- 输出: (bs, n_ctx, width)
binarize
Bases: Function
自定义二值化操作的PyTorch函数实现。 继承自torch.autograd.Function,支持自动求导。 功能:将输入张量根据阈值转换为二值张量(0或1)。
backward(ctx, grad_output)
staticmethod
反向传播:计算输入的梯度。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
ctx
|
上下文对象 |
必需 | |
grad_output
|
输出的梯度,形状同输出 |
必需 |
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
grad_inputs |
输入x的梯度,形状同x(直通估计器) |
forward(ctx, x, threshold=0.5)
staticmethod
前向传播:将输入张量根据阈值二值化。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
ctx
|
上下文对象 |
必需 | |
x
|
输入张量,可以是任意形状 |
必需 | |
threshold
|
二值化阈值,默认值为0.5 |
0.5
|
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
binarized |
二值化后的张量,与x形状相同,值为0或1 |
BinaryFocalLoss
Bases: Module
二分类焦点损失函数,适用于类别不平衡场景
通过降低易分类样本的权重,使得模型在训练时更关注难分类样本 论文: https://arxiv.org/abs/1708.02002
属性:
| 名称 | 类型 | 描述 |
|---|---|---|
gamma |
float
|
调节因子,用于调整困难样本的权重 |
alpha |
float
|
类别权重平衡参数,范围(0,1) |
logits |
bool
|
输入是否为logits(启用sigmoid) |
reduce |
bool
|
是否对损失进行均值降维 |
loss_weight |
float
|
损失权重系数 |
forward(pred, target, **kwargs)
前向计算函数
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
pred
|
Tensor
|
模型预测值,形状为(N) |
必需 |
target
|
Tensor
|
真实标签,形状为(N)。若为类别索引,每个值应为0或1; 若为概率值,形状需与pred一致 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
|
torch.Tensor: 计算得到的损失值 |
BoundaryLoss
Bases: Module
Boundary Loss proposed in: Alexey Bokhovkin et al., Boundary Loss for Remote Sensing Imagery Semantic Segmentation https://arxiv.org/abs/1905.07852
forward(pred_output, gt)
Input
- pred_output: the output from model (before softmax) shape (N, C, H, W)
- gt: ground truth map #这是原来的输入,最新输入为(N, C, H, W) shape (N, H, w)
Return: - boundary loss, averaged over mini-bathc
CenterLoss
Bases: Module
Center loss.
Reference: Wen et al. A Discriminative Feature Learning Approach for Deep Face Recognition. ECCV 2016.
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
num_classes
|
int
|
number of classes. |
3
|
feat_dim
|
int
|
feature dimension. |
3
|
forward(input_x, input_label)
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
x
|
feature matrix with shape (batch_size, feat_dim). |
必需 | |
labels
|
ground truth labels with shape (batch_size). |
必需 |
ContourLoss
Bases: Module
ContourLoss(轮廓损失) 核心思想:同时优化区域一致性和轮廓平滑性,特别适合需要精确边界的分割任务(如医学图像分割、目标边缘分割)。 组成部分: 长度项(length term):通过计算预测图的水平和垂直梯度,惩罚剧烈变化的区域,鼓励生成平滑连续的轮廓。 区域项(region term):惩罚前景区域(target=1)和背景区域(target=0)的预测误差,确保区域内部的一致性
forward(pred, target, weight=10)
target, pred: tensor of shape (B, C, H, W), where target[:,:,region_in_contour] == 1, target[:,:,region_out_contour] == 0. weight: scalar, length term weight.
DiceLoss
Bases: Module
Dice系数损失函数,适用于分割任务
通过测量预测与标签的相似度进行优化,尤其适用于类别不平衡场景 论文: https://arxiv.org/abs/1606.04797
属性:
| 名称 | 类型 | 描述 |
|---|---|---|
smooth |
float
|
平滑系数,防止除零 |
exponent |
int
|
指数参数,控制计算方式 |
loss_weight |
float
|
损失项的缩放权重 |
ignore_index |
int
|
需要忽略的类别索引 |
forward(pred, target, **kwargs)
前向计算函数
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
pred
|
Tensor
|
模型预测值,形状为(B, C, d1, d2, ...) |
必需 |
target
|
Tensor
|
真实标签,形状为(B, d1, d2, ...) |
必需 |
返回:
| 类型 | 描述 |
|---|---|
|
torch.Tensor: 计算得到的损失值 |
FocalLoss
Bases: Module
多分类焦点损失函数,支持类别忽略
适用于多分类任务的焦点损失实现,支持指定忽略类别 论文: https://arxiv.org/abs/1708.02002
属性:
| 名称 | 类型 | 描述 |
|---|---|---|
gamma |
float
|
困难样本调节因子 |
alpha |
float / list
|
类别权重,可设置为列表指定各类别权重 |
reduction |
str
|
损失降维方式,可选'mean'或'sum' |
loss_weight |
float
|
损失项的缩放权重 |
ignore_index |
int
|
需要忽略的类别索引 |
forward(pred, target, **kwargs)
前向计算函数
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
pred
|
Tensor
|
模型预测值,形状为(N, C),C为类别数 |
必需 |
target
|
Tensor
|
真实标签。若为类别索引,形状为(N),值范围为0~C-1; 若为概率,形状需与pred一致 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
|
torch.Tensor: 计算得到的损失值 |
GramLoss
Bases: Module
Gram矩阵损失的实现
该损失函数通过最小化学生模型与教师模型输出特征的Gram矩阵差异, 使学生模型学习到特征间的相关性结构,实现知识蒸馏。 Gram矩阵反映了特征之间的关联强度,是一种结构化知识的表示。 https://github.com/facebookresearch/dinov3/blob/main/dinov3/loss/gram_loss.py
__init__(apply_norm=True, img_level=True, remove_neg=True, remove_only_teacher_neg=False)
初始化GramLoss模块
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
apply_norm
|
是否对特征进行L2归一化。若为True,内积等价于余弦相似度 |
True
|
|
img_level
|
是否在单张图像级别计算Gram矩阵 - True: 输入特征形状为(B, N, D),每张图像单独计算Gram矩阵 - False: 输入特征展平为(B*N, D),计算全局Gram矩阵 |
True
|
|
remove_neg
|
是否将Gram矩阵中的负值置为0,仅保留正相关性 |
True
|
|
remove_only_teacher_neg
|
仅将教师Gram矩阵的负值置为0,并同步清零学生矩阵对应位置 注意:与remove_neg互斥,只能有一个为True |
False
|
引发:
| 类型 | 描述 |
|---|---|
AssertionError
|
当remove_neg和remove_only_teacher_neg同时为True或同时为False时触发 |
forward(output_feats, target_feats, img_level=True)
计算输入特征与目标特征的Gram矩阵之间的MSE损失
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
output_feats
|
学生模型输出的特征张量 形状: (B, N, dim) 若img_level=True;(B*N, dim) 若img_level=False |
必需 | |
target_feats
|
教师模型输出的目标特征张量,形状同output_feats |
必需 | |
img_level
|
是否在图像级别计算Gram矩阵(覆盖类初始化时的同名参数) |
True
|
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
loss |
标量损失值,学生与教师Gram矩阵的MSE差异 |
KoLeoLoss
Bases: Module
Kozachenko-Leonenko熵损失正则化器 源自论文:Sablayrolles et al. - 2018 - Spreading vectors for similarity search 作用:通过最大化特征分布的熵,使向量在特征空间中更分散,提升相似度搜索性能 https://github.com/facebookresearch/dinov3/blob/main/dinov3/loss/koleo_loss.py
forward(student_output, eps=1e-08)
前向传播计算损失
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
student_output
|
BxD
|
学生模型的backbone输出特征,B为批次大小,D为特征维度 |
必需 |
eps
|
数值稳定性参数,防止log(0)或除以零 |
1e-08
|
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
loss |
标量损失值,越小表示特征分布越分散 |
pairwise_NNs_inner(x)
为L2归一化的向量找到成对的最近邻 使用PyTorch实现而非Faiss,以保持在GPU上运行
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
x
|
形状为 (N, D) 的张量,N为样本数,D为特征维度(已L2归一化) |
必需 |
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
indices |
形状为 (N,) 的张量,每个元素表示对应样本的最近邻索引 |
LossVariance
Bases: Module
The instances in target should be labeled
LovaszLoss
Bases: Module
Lovasz损失函数,用于语义分割任务。 支持二值分割、多类别分割和多标签分割三种场景。
论文参考: https://arxiv.org/abs/1705.08790
__init__(mode='binary', class_seen=None, per_image=False, ignore_index=None, loss_weight=1.0)
初始化Lovasz损失函数
参数
mode: 损失计算模式,可选值为"binary"(二值)、"multiclass"(多类别)、"multilabel"(多标签) class_seen: 需要纳入损失计算的类别列表 per_image: 若为True,将按图像计算损失后取平均;否则按整个批次计算 ignore_index: 需要忽略的标签值(不参与损失计算) loss_weight: 损失的权重因子
__repr__()
返回类的字符串表示,便于调试
forward(y_pred, y_true)
计算Lovasz损失
参数
y_pred: 模型预测结果。形状根据模式有所不同: - 二值/多标签模式: (B, H, W) 或 (B, C, H, W) - 多类别模式: (B, C, H, W) y_true: 真实标签。形状: - 二值/多类别模式: (B, H, W) - 多标签模式: (B, C, H, W)
返回
计算得到的损失值
MulticlassDiceLoss
Bases: Module
requires one hot encoded target. Applies DiceLoss on each class iteratively. requires input.shape[0:1] and target.shape[0:1] to be (N, C) where N is batch size and C is number of classes
PatchIoULoss
Bases: Module
PatchIoULoss(补丁 IoULoss) 核心思想:将图像分割为多个子 patch 计算 IoU 损失,增强对局部细节的关注。 实现方式: 将图像按固定大小(64×64)划分为多个子区域。 对每个子区域计算 IoU 损失并累加。 适用场景: 大尺寸图像分割(如遥感图像、高分辨率医学影像)。 需要关注局部细节的任务(如病灶分割中的小肿瘤区域)。
SDFLoss
Bases: Module
基于符号距离函数(SDF)特性的复合损失函数。
该损失函数通过多个约束项,确保模型预测的SDF满足其数学性质和几何特性, 包括SDF值准确性、内外区域区分度、法向量一致性和梯度单位模长约束。
属性
sdf_weight: SDF值约束项的权重系数 inter_weight: 区域区分约束项的权重系数 normal_weight: 法向量一致性约束项的权重系数 grad_weight: 梯度模长约束项的权重系数
__init__(sdf_weight=3000.0, inter_weight=100.0, normal_weight=100.0, grad_weight=50.0)
初始化SDF损失函数的各项权重。
参数
sdf_weight: SDF值约束项的权重,默认3e3 inter_weight: 区域区分约束项的权重,默认1e2 normal_weight: 法向量一致性约束项的权重,默认1e2 grad_weight: 梯度模长约束项的权重,默认5e1
forward(model_output, gt)
计算SDF重建的复合损失。
参数
model_output: 模型输出字典,应包含: - 'model_in': 输入的空间坐标张量,形状为[B, N, 3] - 'model_out': 预测的SDF值,形状为[B, N, 1] gt: 真实标签字典,应包含: - 'sdf': 真实SDF值,形状为[B, N, 1],-1表示无标签 - 'normals': 真实法向量,形状为[B, N, 3]
返回
包含各项损失的字典,键包括: - 'sdf_loss': SDF值约束损失 - 'inter_loss': 区域区分约束损失 - 'normal_loss': 法向量一致性损失 - 'grad_loss': 梯度模长约束损失 - 'total_loss': 总损失(各项加权和)
SSIMUtil
Bases: Module
结构相似性指数(SSIM)工具类,包含SSIM计算、损失函数和结构一致性度量
支持两种计算模式: - 高斯滤波模式:使用高斯窗口计算,精度高 - 平均池化模式:使用平均池化替代高斯滤波,计算更快
__init__(window_size=11, size_average=True, mode='gaussian')
初始化SSIM工具类
参数
window_size: 窗口大小 size_average: 是否对结果进行平均 mode: 计算模式,'gaussian'或'average'
forward(img1, img2)
计算SSIM值
参数
img1: 输入图像1 img2: 输入图像2
返回
ssim值
saliency_structure_consistency(img1, img2)
计算显著性结构一致性(SSIM均值)
ssim_average(img1, img2)
使用平均池化计算SSIM(快速版)
ssim_gaussian(img1, img2)
使用高斯滤波计算SSIM
ssim_loss(img1, img2)
计算SSIM损失 (1 - SSIM)
StructureLoss
Bases: Module
StructureLoss(结构损失) 核心思想:结合加权二元交叉交叉熵(WBCE)和加权 IoU(WIoU),平衡前景背景不平衡问题,同时关注结构一致性。 组成部分: 加权 BCE(wbce):通过权重矩阵weit(基于目标区域的局部均值)赋予前景区域更高的权重,缓解类别不平衡。 加权 IoU(wiou):在 IoU 计算中引入相同权重矩阵,更关注目标结构区域的重叠度。
StyleTransfer
风格迁移模型类,包含风格迁移所需的各种损失函数及前向计算方法 https://zh.d2l.ai/chapter_computer-vision/neural-style.html#id8
__init__(content_weight=1, style_weight=1000.0, tv_weight=10)
初始化风格迁移模型参数
参数
content_weight: 内容损失的权重 style_weight: 风格损失的权重 tv_weight: 总变差损失的权重
content_loss(Y_hat, Y)
staticmethod
计算内容损失
内容损失用于衡量生成图像与内容图像在内容上的差异 通过比较两者的特征图直接实现
参数
Y_hat: 生成图像的特征图 Y: 内容图像的特征图
返回
内容损失值
forward(X, contents_Y_hat, styles_Y_hat, contents_Y, styles_Y_gram)
前向传播计算总损失
参数
X: 生成的图像 contents_Y_hat: 生成图像在内容层的特征图列表 styles_Y_hat: 生成图像在风格层的特征图列表 contents_Y: 内容图像在内容层的特征图列表 styles_Y_gram: 风格图像在风格层的Gram矩阵列表
返回
contents_l: 各内容层的损失列表 styles_l: 各风格层的损失列表 tv_l: 总变差损失 total_loss: 总损失
gram_matrix(x)
staticmethod
计算输入特征图的Gram矩阵
Gram矩阵用于衡量特征图之间的相关性,是风格损失计算的核心 Gram矩阵的元素(i,j)表示第i个特征图与第j个特征图的内积
参数
x: 输入特征图,形状为(batch_size, channels, height, width)
返回
gram: 计算得到的Gram矩阵,形状为(batch_size, channels, channels)
style_loss(Y_hat, gram_Y)
staticmethod
计算风格损失
风格损失用于衡量生成图像与风格图像在风格上的差异 通过比较两者特征图的Gram矩阵实现
参数
Y_hat: 生成图像的特征图 gram_Y: 风格图像特征图的Gram矩阵
返回
风格损失值
tv_loss(Y_hat)
staticmethod
计算总变差损失(Total Variation Loss)
总变差损失用于使生成图像更加平滑,减少高频噪声 通过计算相邻像素之间的差异实现
参数
Y_hat: 生成的图像
返回
总变差损失值
WeightMulticlassDiceLoss
Bases: Module
requires one hot encoded target. Applies DiceLoss on each class iteratively. requires input.shape[0:1] and target.shape[0:1] to be (N, C) where N is batch size and C is number of classes
dice_loss_multi_classes(input, target, epsilon=1e-05, weight=None)
多类别Dice损失函数,用于语义分割任务,计算每个类别的Dice系数并转化为损失。 修改自:https://github.com/wolny/pytorch-3dunet/blob/.../losses.py 的compute_per_channel_dice
参数: input (Tensor): 模型预测的输出,形状为(batch_size, num_classes, [depth, height, width]) target (Tensor): 真实标签的one-hot编码,形状需与input相同 epsilon (float): 平滑系数,防止分母为零,默认为1e-5 weight (Tensor, optional): 各类别的权重,形状应为(num_classes, )
返回: Tensor: 每个类别的Dice损失,形状为(num_classes, )
注意: - 输入和目标的维度必须完全一致 - 本实现暂未使用weight参数,如需加权需后续手动处理
load_checkpoint(path, net, optimizer=None, strict=True, check_shape=True, map_location=None)
加载模型状态,可以支持部分参数加载
加载策略:
- strict==True: 只有名称和形状完全一致的参数才会被加载;
- strict==False且check_shape==True: 仅加载名称存在且形状匹配的参数;
- strict==False且check_shape==False: 加载所有名称匹配的参数,不检查形状;
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
path
|
str
|
模型文件路径 |
必需 |
net
|
Module
|
要加载参数的神经网络模型 |
必需 |
optimizer
|
Optional[Optimizer]
|
优化器,如果需要加载优化器状态 |
None
|
strict
|
bool
|
是否严格匹配模型参数 |
True
|
check_shape
|
bool
|
是否检查参数形状匹配 |
True
|
map_location
|
Optional[str]
|
指定设备映射,例如"cpu"或"cuda:0" |
None
|
返回:
| 名称 | 类型 | 描述 |
|---|---|---|
curr_iter |
int
|
加载了最后迭代次数; |
loss |
float
|
最后损失值; |
extra_info |
Dict
|
额外信息字典; |
pca_color_by_feat(feat, brightness=1.25, center=True)
通过PCA将高维特征转换为RGB颜色,用于可视化。
该函数使用主成分分析(PCA)对输入特征进行降维, 组合前6个主成分生成3维颜色向量,并将其归一化到[0, 1]范围, 适用于作为RGB颜色值进行点云等数据的可视化。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
feat
|
Tensor
|
输入的高维特征张量。 形状应为(num_points, feature_dim),其中num_points是点的数量, feature_dim是每个特征的维度。 |
必需 |
brightness
|
(float, 可选)
|
颜色亮度的缩放因子。 值越高,整体颜色越明亮。默认值为1.25。 |
1.25
|
center
|
(bool, 可选)
|
在执行PCA之前是否对特征进行中心化(减去均值)。 默认值为True。 |
True
|
返回:
| 类型 | 描述 |
|---|---|
|
torch.Tensor: 归一化到[0, 1]范围的RGB颜色值。 形状为(num_points, 3),每行代表(R, G, B)三个通道的颜色值。 |
save_checkpoint(save_path, network, loss, optimizer=None, curr_iter=0, extra_info=None, save_best_only=True)
保存模型状态、优化器状态、当前迭代次数和损失值; save_best_only开启后,直接比较已保存模型的loss(避免硬件故障引起保存问题)
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
save_path
|
str
|
包含模型保存路径等参数的配置对象 |
必需 |
network
|
Module
|
神经网络模型 |
必需 |
optimizer
|
Optional[Optimizer]
|
优化器 |
None
|
loss
|
float
|
当前损失值 |
必需 |
curr_iter
|
int
|
当前迭代次数 |
0
|
extra_info
|
Optional[Dict]
|
可选的额外信息字典,用于保存其他需要的信息 |
None
|
save_best_only
|
bool
|
是否仅在损失更优时保存模型,默认为True |
True
|
set_global_seeds(seed=1024, cudnn_enable=False)
设置全局随机种子,确保Python、NumPy、PyTorch等环境的随机数生成器同步,提升实验可复现性。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
seed
|
int
|
要使用的基础随机数种子,默认值为1024。 |
1024
|
cudnn_enable
|
bool
|
是否将CuDNN设置为确定性模式,启用后可能会影响性能但提高可复现性,默认值为False。 |
False
|
set_ssl(SteamToolsCertificate_path)
将steam++的证书写入到ssl中,防止requests.exceptions.SSLError报错 SteamToolsCertificate_path = os.path.join(os.path.dirname(file),"data","SteamTools.Certificate.pfx")
报告模块API
Windows工具API
@path :sindre_package -> py2pyd.py
@IDE :PyCharm
@Author :sindre
@Email :yx@mviai.com
@Date :2024/6/17 16:32
@Version: V0.1
@License: (C)Copyright 2021-2023 , UP3D
@Reference:
ip_bind
Bases: Thread
实现本地0.0.0.0:8000 <--> 远程端口 内网穿透
set_ip(remote_ip, remote_port)
设置远程ip及端口
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
remote_ip
|
str
|
远程ip |
必需 |
remote_port
|
str
|
远程端口 |
必需 |
Returns:
tcp_mapping_qt
Bases: Thread
TCP 传输线程
check_port(port)
检测win端口是否被占用
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
port
|
int
|
端口号 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
bool
|
是否被占用 |
download_url_file(url, package_path='test.zip')
下载网络文件
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
url
|
str
|
文件下载地址 |
必需 |
package_path
|
str
|
保存路径 |
'test.zip'
|
返回:
| 类型 | 描述 |
|---|---|
bool
|
下载是否成功 |
exe2nsis(work_dir, files_to_compress, exe_name, appname='AI', version='1.0.0.0', author='SindreYang', license='', icon_old='')
将exe进行nsis封装成安装程序;
Notes
files_to_compress =[f"{self.work_dir}/{i}" for i in ["app", "py", "third", "app.exe", "app.py", "requirements.txt"]]
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
work_dir
|
str
|
生成的路径 |
必需 |
files_to_compress
|
list
|
需要转换的文件夹/文件列表 |
必需 |
exe_name
|
str
|
指定主运行程序,快捷方式也是用此程序生成 |
必需 |
appname
|
str
|
产品名 |
'AI'
|
version
|
str
|
版本号--必须为 X.X.X.X |
'1.0.0.0'
|
author
|
str
|
作者 |
'SindreYang'
|
license
|
str
|
licence.txt协议路径 |
''
|
icon_old
|
str
|
图标 |
''
|
is_service_exists(service_name)
使用sc query命令来查询服务
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
service_name
|
str
|
服务名 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
bool
|
返回是否存在服务 |
kill_process_using_port(server_port)
请求管理员权限,并强制释放端口
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
server_port
|
int
|
端口号 |
必需 |
返回:
| 类型 | 描述 |
|---|---|
bool
|
端口是否成功释放 |
pip_install(package_name='', target_dir='', requirements_path='')
模拟pip安装
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
package_name
|
str
|
包名 |
''
|
target_dir
|
str
|
安装目录,为空,则自动安装到当前环境下 |
''
|
requirements_path
|
str
|
requirementsTxT路径 |
''
|
py2pyd(source_path, clear_py=False)
将目录下所有py文件编译成pyd文件。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
source_path
|
str
|
源码目录 |
必需 |
clear_py
|
bool
|
是否编译后清除py文件,注意备份。 |
False
|
python_installer(install_dir, version='3.9.6')
python自动化安装
Notes
默认从 https://mirrors.huaweicloud.com/python/{version}/python-{version}-embed-amd64.zip 下载安装
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
install_dir
|
str
|
安装位置 |
必需 |
version
|
str
|
版本号 |
'3.9.6'
|
zip_extract(zip_path, install_dir)
将zip文件解压
Args: zip_path: zip文件路径 install_dir: 解压目录
返回:
| 类型 | 描述 |
|---|---|
bool
|
解压是否成功 |
set_windows_alpha(alpha=255, class_name='Shell_TrayWnd')
通过查找class_name,强制用于设置任务栏透明程度
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
alpha
|
int
|
透明度,(0--完全透明,255--完全不透明) |
255
|
class_name
|
str
|
窗口名 |
'Shell_TrayWnd'
|
部署相关 API
OnnxInfer
__call__(inputs)
执行模型推理
__init__(onnx_path, providers=[('CPUExecutionProvider', {})], enable_log=False)
ONNX模型推理类,支持多种推理后端(CPU/GPU等)
参数
onnx_path: ONNX模型文件路径 providers: 推理提供者列表,格式为[(provider_name, options_dict), ...]
convert_opset_version(save_path, target_version)
转换ONNX模型的Opset版本 :param save_path: 保存路径 :param target_version: 目标Opset版本(如16)
dynamic_input_shape(save_path, dynamic_dims)
设置ONNX模型的输入为动态尺寸(支持多输入,None表示动态维度) :param dynamic_dims: 动态维度列表,如 [[None, 3, None, 480], [None, 3, None, 480]] 每个子列表对应一个输入的维度,None表示该维度动态可变
fix_input_shape(save_path, input_shapes)
固定ONNX模型的输入尺寸(支持多输入) :param save_path: 保存路径 :param input_shapes: 输入形状列表,如 [[1,3,416,480], [1,3,416,480]] or [[1,3,416,480]]
get_session(onnx_path, providers, enable_log=False)
加载并验证ONNX模型,创建推理会话
optimizer(save_onnx)
优化并简化ONNX模型
test_performance(loop=10, warmup=3)
测试模型推理速度
SimpleSharedMemory
get_status()
获取状态标志
read()
读取数据并清空内存
set_status(status)
设置状态标志:0-空,1-已写入
write(array)
写入数据,如果内存未清空则等待
TRTInfer
__call__(data)
执行推理
build_engine(onnx_path, engine_path, max_workspace_size=4 << 30, fp16=False, dynamic_shape_profile=None, hardware_compatibility='', optimization_level=3, version_compatible=False)
从ONNX模型构建TensorRT引擎
参数
onnx_path (str): ONNX模型路径 engine_path (str, optional): 引擎保存路径 max_workspace_size (int, optional): 最大工作空间大小,默认为4GB fp16 (bool, optional): 是否启用FP16精度 dynamic_shape_profile (dict, optional): 动态形状配置,格式为: { "input_name": { "min": (1, 3, 224, 224), # 最小形状 "opt": (4, 3, 224, 224), # 优化形状 "max": (8, 3, 224, 224) # 最大形状 } } hardware_compatibility (str, optional): 硬件兼容性级别,可选值: - "": 默认(最快) - "same_sm": 相同计算能力(其次) - "ampere_plus": Ampere及更高架构(最慢) Pascal(10系)、Volta(V100)、Turing(20系)、Ampere(30系)、 Ada(40系)、Hopper(H100)、Blackwell(50系) optimization_level (int): 优化级别,默认最优级别3; ・等级0:通过禁用动态内核生成并选择执行成功的第一个策略,实现最快的编译。这也不会考虑计时缓存。 ・等级1:可用策略按启发式方法排序,但仅测试排名靠前的策略以选择最佳策略。如果生成动态内核,其编译优化程度较低。 ・等级2:可用策略按启发式方法排序,但仅测试最快的策略以选择最佳策略。 ・等级3:应用启发式方法,判断静态预编译内核是否适用,或者是否必须动态编译新内核。 ・等级4:始终编译动态内核。 ・等级5:始终编译动态内核,并将其与静态内核进行比较。 version_compatible (bool): 是否启用版本兼容模式(8.6构建的引擎可以在10.x上运行)
load_model(engine_path)
从TensorRT引擎文件加载模型
test_performance(loop=10, warmup=3)
测试推理性能(自动生成随机输入)
参数
loop: 正式测试循环次数 warmup: 预热次数
grid_sample(input, grid, align_corners=True)
自适应版本的grid_sample,根据输入维度自动选择2D或3D实现
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
input
|
Tensor
|
输入图像 - 对于2D采样: 形状为 (N, C, H, W) - 对于3D采样: 形状为 (N, C, D, H, W) |
必需 |
grid
|
Tensor
|
采样网格 - 对于2D采样: 形状为 (N, Hg, Wg, 2) - 对于3D采样: 形状为 (N, D_out, H_out, W_out, 3) |
必需 |
align_corners
|
bool
|
坐标归一化方式,与F.grid_sample的align_corners参数含义一致 |
True
|
返回:
| 类型 | 描述 |
|---|---|
|
torch.Tensor: 采样结果 - 对于2D采样: 形状为 (N, C, Hg, Wg) - 对于3D采样: 形状为 (N, C, D_out, H_out, W_out) |
引发:
| 类型 | 描述 |
|---|---|
ValueError
|
如果输入维度不是4D(2D)或5D(3D) |
ValueError
|
如果grid的最后一维不是2(2D)或3(3D) |
Notes
该函数根据输入维度自动调用grid_sample_2d或grid_sample_3d 等效于PyTorch的F.grid_sample,padding_mode='zeros'
grid_sample_2d(im, grid, align_corners=False)
2D版本的grid_sample,使用双线性插值对输入像素进行采样
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
im
|
Tensor
|
输入特征图,形状 (N, C, H, W) |
必需 |
grid
|
Tensor
|
点坐标,形状 (N, Hg, Wg, 2),最后一维是(x,y)坐标 |
必需 |
align_corners
|
bool
|
坐标归一化方式,与F.grid_sample的align_corners参数含义一致 |
False
|
返回:
| 类型 | 描述 |
|---|---|
|
torch.Tensor: 采样结果,形状为 (N, C, Hg, Wg) |
Notes
等效于PyTorch的F.grid_sample,padding_mode='zeros'
grid_sample_3d(image, grid, align_corners=False)
3D版本的grid_sample,功能等同于F.grid_sample(image, grid_3d, align_corners=True) 支持align_corners参数,控制坐标归一化方式
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
image
|
Tensor
|
输入图像,形状为 (N, C, D, H, W) |
必需 |
grid
|
Tensor
|
采样网格,形状为 (N, D_out, H_out, W_out, 3),最后一维是(x,y,z)坐标 |
必需 |
align_corners
|
bool
|
坐标归一化方式,与F.grid_sample的align_corners参数含义一致 |
False
|
返回:
| 类型 | 描述 |
|---|---|
|
torch.Tensor: 采样结果,形状为 (N, C, D_out, H_out, W_out) |
Notes
等效于PyTorch的F.grid_sample,padding_mode='zeros'
日志工具 API
CustomLogger
一个使用 loguru 库的自定义日志记录器类,支持多进程、print重定向、日志分级存储等。
属性:
| 名称 | 类型 | 描述 |
|---|---|---|
logger |
logger
|
配置好的 loguru 日志记录器实例。 |
__init__(logger_name=None, level='DEBUG', log_dir='logs', console_output=True, file_output=False, capture_print=False, filter_log=None)
初始化 CustomLogger。
参数:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
logger_name
|
str
|
日志记录器名称。 |
None
|
level
|
str
|
日志级别,默认为 'DEBUG'。 |
'DEBUG'
|
log_dir
|
str
|
日志文件存储目录。 |
'logs'
|
console_output
|
bool
|
是否启用控制台输出。 |
True
|
file_output
|
bool
|
是否启用文件输出。 |
False
|
capture_print
|
bool
|
是否捕获 print 输出。 |
False
|
filter_log
|
callable
|
自定义日志过滤函数。 |
None
|
get_logger()
获取配置好的日志记录器实例。